![[转]操作系统核心知识点](https://cdn.nlark.com/yuque/0/2021/svg/1484158/1609726829272-e77b939e-eefd-4282-8f0a-68c97aa7dfe5.svg)
[转]操作系统核心知识点
本文转载自:5万字、97 张图总结操作系统核心知识点 - 程序员cxuan - 博客园部分内容自行添加这不是一篇教你如何创建一个操作系统的文章,相反,这是一篇指导性文章,教你从几个方面来理解操作系统。首先你需要知道你为什么要看这篇文章以及为什么要学习操作系统。搞清楚几个问题首先你要搞明白你学习...
- 部分内容自行添加
这不是一篇教你如何创建一个操作系统的文章,相反,这是一篇指导性文章,教你从几个方面来理解操作系统。首先你需要知道你为什么要看这篇文章以及为什么要学习操作系统。
搞清楚几个问题
首先你要搞明白你学习操作系统的目的是什么?操作系统的重要性如何?学习操作系统会给我带来什么?下面我会从这几个方面为你回答下。
操作系统也是一种软件,但是操作系统是一种非常复杂的软件。操作系统提供了几种抽象模型
- 文件:对 I/O 设备的抽象
- 虚拟内存:对程序存储器的抽象
- 进程:对一个正在运行程序的抽象
- 虚拟机:对整个操作系统的抽象
这些抽象和我们的日常开发息息相关。搞清楚了操作系统是如何抽象的,才能培养我们的抽象性思维和开发思路。
很多问题都和操作系统相关,操作系统是解决这些问题的基础。如果你不学习操作系统,可能会想着从框架层面来解决,那是你了解的还不够深入,当你学习了操作系统后,能够培养你的全局性思维。
学习操作系统我们能够有效的解决并发问题,并发几乎是互联网的重中之重了,这也从侧面说明了学习操作系统的重要性。
学习操作系统的重点不是让你从头制造一个操作系统,而是告诉你操作系统是如何工作的,能够让你对计算机底层有所了解,打实你的基础。
相信你一定清楚什么是编程
Data structures + Algorithms = Programming
操作系统内部会涉及到众多的数据结构和算法描述,能够让你了解算法的基础上,让你编写更优秀的程序。
我认为可以把计算机比作一栋楼
计算机的底层相当于就是楼的根基,计算机应用相当于就是楼的外形,而操作系统就相当于是告诉你大楼的构造原理,编写高质量的软件就相当于是告诉你构建一个稳定的房子。
认识操作系统
在了解操作系统前,你需要先知道一下什么是计算机系统:现代计算机系统由一个或多个处理器、主存、打印机、键盘、鼠标、显示器、网络接口以及各种输入/输出设备构成的系统。这些都属于硬件的范畴。我们程序员不会直接和这些硬件打交道,并且每位程序员不可能会掌握所有计算机系统的细节。
所以计算机科学家在硬件的基础之上,安装了一层软件,这层软件能够根据用户输入的指令达到控制硬件的效果,从而满足用户的需求,这样的软件称为 操作系统,它的任务就是为用户程序提供一个更好、更简单、更清晰的计算机模型。也就是说,操作系统相当于是一个中间层,为用户层和硬件提供各自的借口,屏蔽了不同应用和硬件之间的差异,达到统一标准的作用。
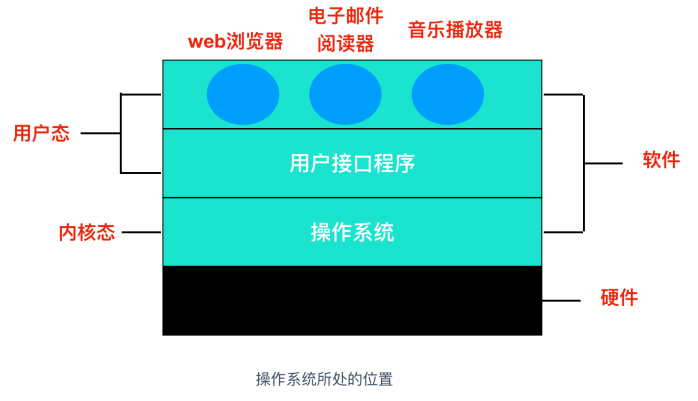
上面一个操作系统的简化图,最底层是硬件,硬件包括芯片、电路板、磁盘、键盘、显示器等我们上面提到的设备,在硬件之上是软件。大部分计算机有两种运行模式:内核态 和 用户态,软件中最基础的部分是操作系统,它运行在 内核态 中。操作系统具有硬件的访问权,可以执行机器能够运行的任何指令。软件的其余部分运行在 用户态 下。
在大概了解到操作系统之后,我们先来认识一下硬件都有哪些
计算机硬件
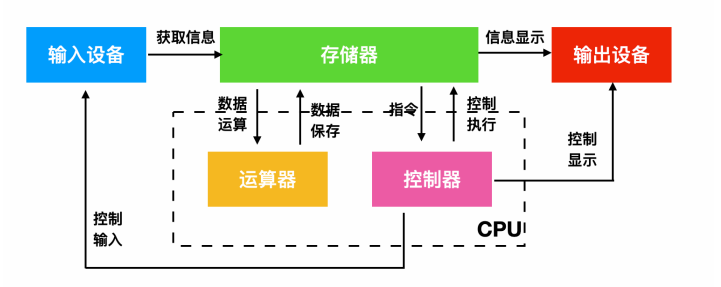
计算机硬件是计算机的重要组成部分,其中包含了 5 个重要的组成部分:运算器、控制器、存储器、输入设备、输出设备。
运算器:运算器最主要的功能是对数据和信息进行加工和运算。它是计算机中执行算数和各种逻辑运算的部件。运算器的基本运算包括加、减、乘、除、移位等操作,这些是由算术逻辑单元(Arithmetic&logical Unit)实现的。而运算器主要由算数逻辑单元和寄存器构成。控制器:指按照指定顺序改变主电路或控制电路的部件,它主要起到了控制命令执行的作用,完成协调和指挥整个计算机系统的操作。控制器是由程序计数器、指令寄存器、解码译码器等构成。
运算器和控制器共同组成了 CPU
存储器:存储器就是计算机的记忆设备,顾名思义,存储器可以保存信息。存储器分为两种,一种是主存,也就是内存,它是 CPU 主要交互对象,还有一种是外存,比如硬盘软盘等。下面是现代计算机系统的存储架构输入设备:输入设备是给计算机获取外部信息的设备,它主要包括键盘和鼠标。
输出设备:输出设备是给用户呈现根据输入设备获取的信息经过一系列的计算后得到显示的设备,它主要包括显示器、打印机等。
这五部分也是冯诺伊曼的体系结构,它认为计算机必须具有如下功能:
把需要的程序和数据送至计算机中。必须具有长期记忆程序、数据、中间结果及最终运算结果的能力。能够完成各种算术、逻辑运算和数据传送等数据加工处理的能力。能够根据需要控制程序走向,并能根据指令控制机器的各部件协调操作。能够按照要求将处理结果输出给用户。
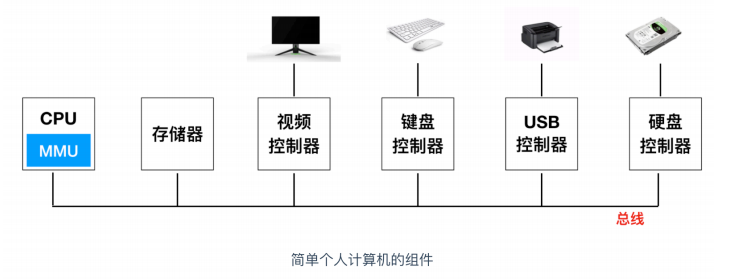
下面是一张 intel 家族产品图,是一个详细的计算机硬件分类,我们在根据图中涉及到硬件进行介绍
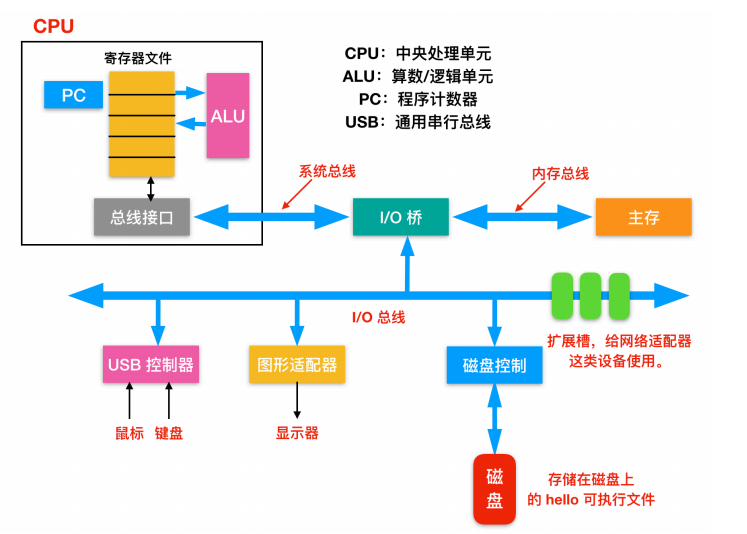
总线(Buses):在整个系统中运行的是称为总线的电气管道的集合,这些总线在组件之间来回传输字节信息。通常总线被设计成传送定长的字节块,也就是字(word)。字中的字节数(字长)是一个基本的系统参数,各个系统中都不尽相同。现在大部分的字都是 4 个字节(32 位)或者 8 个字节(64 位)。
I/O 设备(I/O Devices):Input/Output 设备是系统和外部世界的连接。上图中有四类 I/O 设备:用于用户输入的键盘和鼠标,用于用户输出的显示器,一个磁盘驱动用来长时间的保存数据和程序。刚开始的时候,可执行程序就保存在磁盘上。
每个I/O 设备连接 I/O 总线都被称为控制器(controller)或者是适配器(Adapter)。控制器和适配器之间的主要区别在于封装方式。控制器是 I/O 设备本身或者系统的主印制板电路(通常称作主板)上的芯片组。而适配器则是一块插在主板插槽上的卡。无论组织形式如何,它们的最终目的都是彼此交换信息。主存(Main Memory),主存是一个临时存储设备,而不是永久性存储,磁盘是永久性存储的设备。主存既保存程序,又保存处理器执行流程所处理的数据。从物理组成上说,主存是由一系列DRAM(dynamic random access memory)动态随机存储构成的集合。逻辑上说,内存就是一个线性的字节数组,有它唯一的地址编号,从 0 开始。一般来说,组成程序的每条机器指令都由不同数量的字节构成,C 程序变量相对应的数据项的大小根据类型进行变化。比如,在 Linux 的 x86-64 机器上,short 类型的数据需要 2 个字节,int 和 float 需要 4 个字节,而 long 和 double 需要 8 个字节。
处理器(Processor),CPU(central processing unit)或者简单的处理器,是解释(并执行)存储在主存储器中的指令的引擎。处理器的核心大小为一个字的存储设备(或寄存器),称为程序计数器(PC)。在任何时刻,PC 都指向主存中的某条机器语言指令(即含有该条指令的地址)。
从系统通电开始,直到系统断电,处理器一直在不断地执行程序计数器指向的指令,再更新程序计数器,使其指向下一条指令。处理器根据其指令集体系结构定义的指令模型进行操作。在这个模型中,指令按照严格的顺序执行,执行一条指令涉及执行一系列的步骤。处理器从程序计数器指向的内存中读取指令,解释指令中的位,执行该指令指示的一些简单操作,然后更新程序计数器以指向下一条指令。指令与指令之间可能连续,可能不连续(比如 jmp 指令就不会顺序读取)
下面是 CPU 可能执行简单操作的几个步骤
加载(Load):从主存中拷贝一个字节或者一个字到内存中,覆盖寄存器先前的内容存储(Store):将寄存器中的字节或字复制到主存储器中的某个位置,从而覆盖该位置的先前内容
操作(Operate):把两个寄存器的内容复制到ALU(Arithmetic logic unit)。把两个字进行算术运算,并把结果存储在寄存器中,重写寄存器先前的内容。
算术逻辑单元(ALU)是对数字二进制数执行算术和按位运算的组合数字电子电路。
跳转(jump):从指令中抽取一个字,把这个字复制到程序计数器(PC)中,覆盖原来的值
进程和线程
关于进程和线程,你需要理解下面这张脑图中的重点

进程
操作系统中最核心的概念就是 进程,进程是对正在运行中的程序的一个抽象。操作系统的其他所有内容都是围绕着进程展开的。
在多道程序处理的系统中,CPU 会在进程间快速切换,使每个程序运行几十或者几百毫秒。然而,严格意义来说,在某一个瞬间,CPU 只能运行一个进程,然而我们如果把时间定位为 1 秒内的话,它可能运行多个进程。这样就会让我们产生并行的错觉。因为 CPU 执行速度很快,进程间的换进换出也非常迅速,因此我们很难对多个并行进程进行跟踪。所以,操作系统的设计者开发了用于描述并行的一种概念模型(顺序进程),使得并行更加容易理解和分析。
进程模型
一个进程就是一个正在执行的程序的实例,进程也包括程序计数器、寄存器和变量的当前值。从概念上来说,每个进程都有各自的虚拟 CPU,但是实际情况是 CPU 会在各个进程之间进行来回切换。
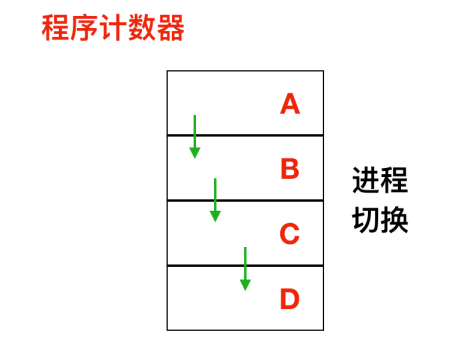
如上图所示,这是一个具有 4 个程序的多道处理程序,在进程不断切换的过程中,程序计数器也在不同的变化。
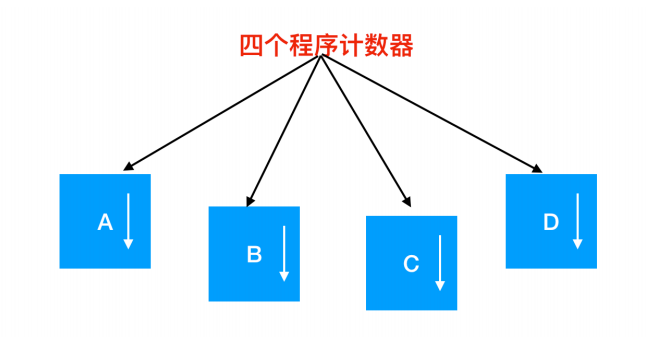
在上图中,这 4 道程序被抽象为 4 个拥有各自控制流程(即每个自己的程序计数器)的进程,并且每个程序都独立的运行。当然,实际上只有一个物理程序计数器,每个程序要运行时,其逻辑程序计数器会装载到物理程序计数器中。当程序运行结束后,其物理程序计数器就会是真正的程序计数器,然后再把它放回进程的逻辑计数器中。
从下图我们可以看到,在观察足够长的一段时间后,所有的进程都运行了,但在任何一个给定的瞬间仅有一个进程真正运行。
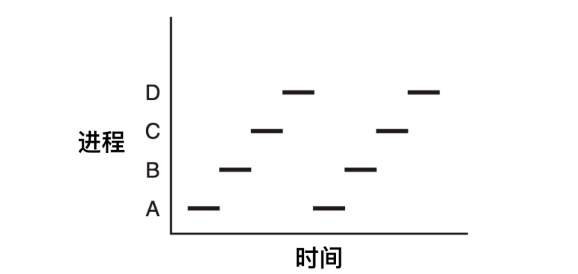
因此,当我们说一个 CPU 只能真正一次运行一个进程的时候,即使有 2 个核(或 CPU),每一个核也只能一次运行一个线程。
由于 CPU 会在各个进程之间来回快速切换,所以每个进程在 CPU 中的运行时间是无法确定的。并且当同一个进程再次在 CPU 中运行时,其在 CPU 内部的运行时间往往也是不固定的。
这里的关键思想是认识到一个进程所需的条件,进程是某一类特定活动的总和,它有程序、输入输出以及状态。
进程的创建
操作系统需要一些方式来创建进程。下面是一些创建进程的方式
- 系统初始化(init):启动操作系统时,通常会创建若干个进程。
- 正在运行的程序执行了创建进程的系统调用(比如 fork)
- 用户请求创建一个新进程:在许多交互式系统中,输入一个命令或者双击图标就可以启动程序,以上任意一种操作都可以选择开启一个新的进程,在基本的 UNIX 系统中运行 X,新进程将接管启动它的窗口。
- 初始化一个批处理工作
从技术上讲,在所有这些情况下,让现有流程执行流程是通过创建系统调用来创建新流程的。该进程可能是正在运行的用户进程,是从键盘或鼠标调用的系统进程或批处理程序。这些就是系统调用创建新进程的过程。该系统调用告诉操作系统创建一个新进程,并直接或间接指示在其中运行哪个程序。
在 UNIX 中,仅有一个系统调用来创建一个新的进程,这个系统调用就是 fork。这个调用会创建一个与调用进程相关的副本。在 fork 后,一个父进程和子进程会有相同的内存映像,相同的环境字符串和相同的打开文件。
在 Windows 中,情况正相反,一个简单的 Win32 功能调用 CreateProcess,会处理流程创建并将正确的程序加载到新的进程中。这个调用会有 10 个参数,包括了需要执行的程序、输入给程序的命令行参数、各种安全属性、有关打开的文件是否继承控制位、优先级信息、进程所需要创建的窗口规格以及指向一个结构的指针,在该结构中新创建进程的信息被返回给调用者。在 Windows 中,从一开始父进程的地址空间和子进程的地址空间就是不同的。
进程的终止
进程在创建之后,它就开始运行并做完成任务。然而,没有什么事儿是永不停歇的,包括进程也一样。进程早晚会发生终止,但是通常是由于以下情况触发的
正常退出(自愿的): 多数进程是由于完成了工作而终止。当编译器完成了所给定程序的编译之后,编译器会执行一个系统调用告诉操作系统它完成了工作。这个调用在 UNIX 中是exit,在 Windows 中是ExitProcess。错误退出(自愿的):比如执行一条不存在的命令,于是编译器就会提醒并退出。
严重错误(非自愿的)被其他进程杀死(非自愿的): 某个进程执行系统调用告诉操作系统杀死某个进程。在 UNIX 中,这个系统调用是 kill。在 Win32 中对应的函数是TerminateProcess(注意不是系统调用)。
进程的层次结构
在一些系统中,当一个进程创建了其他进程后,父进程和子进程就会以某种方式进行关联。子进程它自己就会创建更多进程,从而形成一个进程层次结构。
UNIX 进程体系
在 UNIX 中,进程和它的所有子进程以及子进程的子进程共同组成一个进程组。当用户从键盘中发出一个信号后,该信号被发送给当前与键盘相关的进程组中的所有成员(它们通常是在当前窗口创建的所有活动进程)。每个进程可以分别捕获该信号、忽略该信号或采取默认的动作,即被信号 kill 掉。整个操作系统中所有的进程都隶属于一个单个以 init 为根的进程树。

Windows 进程体系
相反,Windows 中没有进程层次的概念,Windows 中所有进程都是平等的,唯一类似于层次结构的是在创建进程的时候,父进程得到一个特别的令牌(称为句柄),该句柄可以用来控制子进程。然而,这个令牌可能也会移交给别的操作系统,这样就不存在层次结构了。而在 UNIX 中,进程不能剥夺其子进程的 进程权。(这样看来,还是 Windows 比较渣)。
进程状态
尽管每个进程是一个独立的实体,有其自己的程序计数器和内部状态,但是,进程之间仍然需要相互帮助。当一个进程开始运行时,它可能会经历下面这几种状态
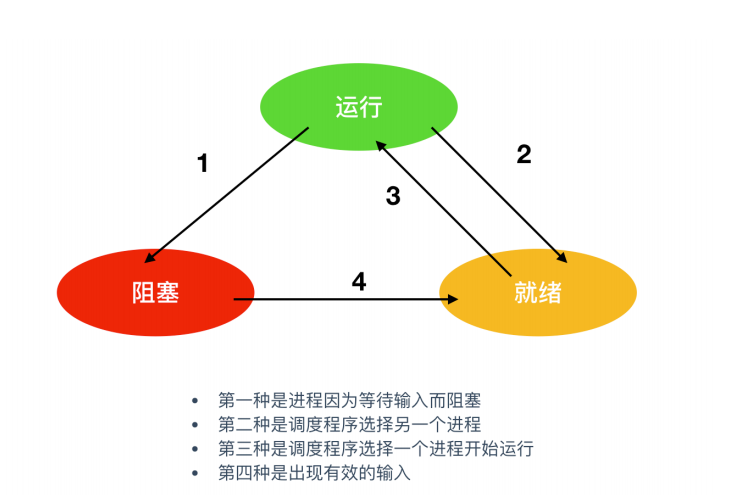
图中会涉及三种状态
运行态,运行态指的就是进程实际占用 CPU 时间片运行时就绪态,就绪态指的是可运行,但因为其他进程正在运行而处于就绪状态
阻塞态,除非某种外部事件发生,否则进程不能运行
进程的实现
操作系统为了执行进程间的切换,会维护着一张表,这张表就是 进程表(process table)。每个进程占用一个进程表项。该表项包含了进程状态的重要信息,包括程序计数器、堆栈指针、内存分配状况、所打开文件的状态、账号和调度信息,以及其他在进程由运行态转换到就绪态或阻塞态时所必须保存的信息。
下面展示了一个典型系统中的关键字段

第一列内容与进程管理有关,第二列内容与 存储管理有关,第三列内容与文件管理有关。
现在我们应该对进程表有个大致的了解了,就可以在对单个 CPU 上如何运行多个顺序进程的错觉做更多的解释。与每一 I/O 类相关联的是一个称作 中断向量(interrupt vector) 的位置(靠近内存底部的固定区域)。它包含中断服务程序的入口地址。假设当一个磁盘中断发生时,用户进程 3 正在运行,则中断硬件将程序计数器、程序状态字、有时还有一个或多个寄存器压入堆栈,计算机随即跳转到中断向量所指示的地址。这就是硬件所做的事情。然后软件就随即接管一切剩余的工作。
当中断结束后,操作系统会调用一个 C 程序来处理中断剩下的工作。在完成剩下的工作后,会使某些进程就绪,接着调用调度程序,决定随后运行哪个进程。然后将控制权转移给一段汇编语言代码,为当前的进程装入寄存器值以及内存映射并启动该进程运行,下面显示了中断处理和调度的过程。
- 硬件压入堆栈程序计数器等
- 硬件从中断向量装入新的程序计数器
- 汇编语言过程保存寄存器的值
- 汇编语言过程设置新的堆栈
- C 中断服务器运行(典型的读和缓存写入)
- 调度器决定下面哪个程序先运行
- C 过程返回至汇编代码
- 汇编语言过程开始运行新的当前进程
一个进程在执行过程中可能被中断数千次,但关键每次中断后,被中断的进程都返回到与中断发生前完全相同的状态。
线程
在传统的操作系统中,每个进程都有一个地址空间和一个控制线程。事实上,这是大部分进程的定义。不过,在许多情况下,经常存在同一地址空间中运行多个控制线程的情形,这些线程就像是分离的进程。下面我们就着重探讨一下什么是线程
线程的使用
或许这个疑问也是你的疑问,为什么要在进程的基础上再创建一个线程的概念,准确的说,这其实是进程模型和线程模型的讨论,回答这个问题,可能需要分三步来回答
- 多线程之间会共享同一块地址空间和所有可用数据的能力,这是进程所不具备的
- 线程要比进程
更轻量级,由于线程更轻,所以它比进程更容易创建,也更容易撤销。在许多系统中,创建一个线程要比创建一个进程快 10 - 100 倍。
- 第三个原因可能是性能方面的探讨,如果多个线程都是 CPU 密集型的,那么并不能获得性能上的增强,但是如果存在着大量的计算和大量的 I/O 处理,拥有多个线程能在这些活动中彼此重叠进行,从而会加快应用程序的执行速度
经典的线程模型
进程中拥有一个执行的线程,通常简写为 线程(thread)。线程会有程序计数器,用来记录接着要执行哪一条指令;线程实际上 CPU 上调度执行的实体。
下图我们可以看到三个传统的进程,每个进程有自己的地址空间和单个控制线程。每个线程都在不同的地址空间中运行
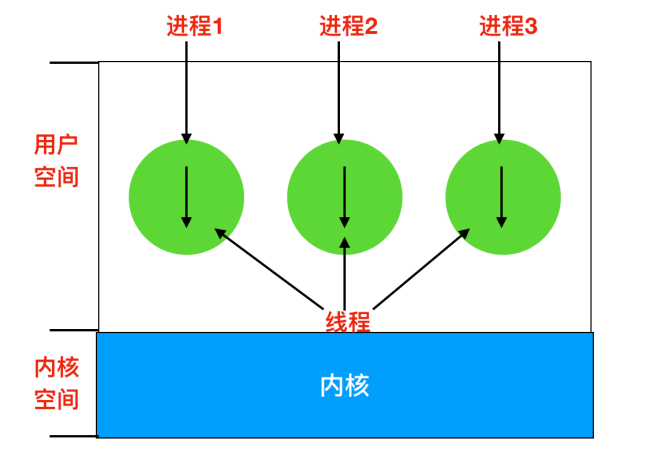
下图中,我们可以看到有一个进程三个线程的情况。每个线程都在相同的地址空间中运行。
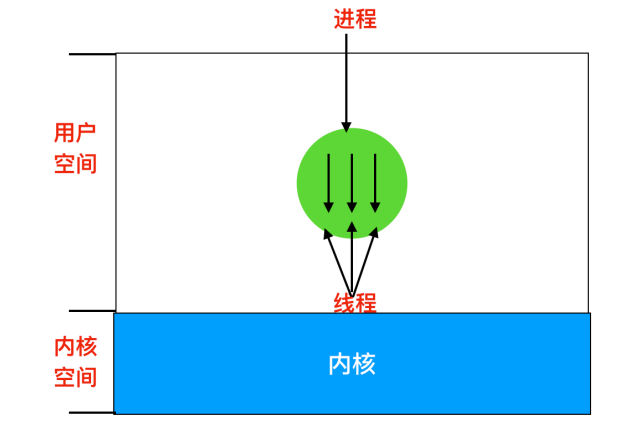
线程不像是进程那样具备较强的独立性。同一个进程中的所有线程都会有完全一样的地址空间,这意味着它们也共享同样的全局变量。由于每个线程都可以访问进程地址空间内每个内存地址,因此一个线程可以读取、写入甚至擦除另一个线程的堆栈。线程之间除了共享同一内存空间外,还具有如下不同的内容

上图左边的是同一个进程中每个线程共享的内容,上图右边是每个线程中的内容。也就是说左边的列表是进程的属性,右边的列表是线程的属性。
线程之间的状态转换和进程之间的状态转换是一样的。
每个线程都会有自己的堆栈,如下图所示
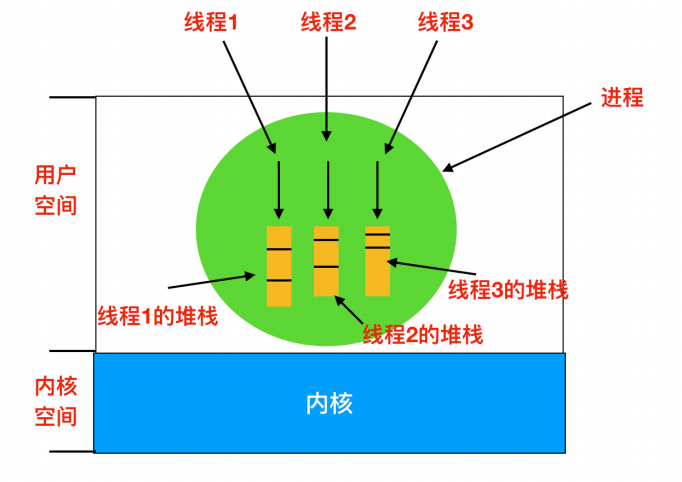
线程系统调用
进程通常会从当前的某个单线程开始,然后这个线程通过调用一个库函数(比如 thread_create )创建新的线程。线程创建的函数会要求指定新创建线程的名称。创建的线程通常都返回一个线程标识符,该标识符就是新线程的名字。
当一个线程完成工作后,可以通过调用一个函数(比如 thread_exit)来退出。紧接着线程消失,状态变为终止,不能再进行调度。在某些线程的运行过程中,可以通过调用函数例如 thread_join ,表示一个线程可以等待另一个线程退出。这个过程阻塞调用线程直到等待特定的线程退出。在这种情况下,线程的创建和终止非常类似于进程的创建和终止。
另一个常见的线程是调用 thread_yield,它允许线程自动放弃 CPU 从而让另一个线程运行。这样一个调用还是很重要的,因为不同于进程,线程是无法利用时钟中断强制让线程让出 CPU 的。
POSIX 线程
POSIX 线程 通常称为 pthreads是一种独立于语言而存在的执行模型,以及并行执行模型。

它允许程序控制时间上重叠的多个不同的工作流程。每个工作流程都称为一个线程,可以通过调用 POSIX Threads API 来实现对这些流程的创建和控制。可以把它理解为线程的标准。
POSIX Threads 的实现在许多类似且符合POSIX的操作系统上可用,例如 FreeBSD、NetBSD、OpenBSD、Linux、macOS、Android、Solaris,它在现有 Windows API 之上实现了pthread。
IEEE 是世界上最大的技术专业组织,致力于为人类的利益而发展技术。
线程调用 | 描述 |
pthread_create | 创建一个新线程 |
pthread_exit | 结束调用的线程 |
pthread_join | 等待一个特定的线程退出 |
pthread_yield | 释放 CPU 来运行另外一个线程 |
pthread_attr_init | 创建并初始化一个线程的属性结构 |
pthread_attr_destory | 删除一个线程的属性结构 |
所有的 Pthreads 都有特定的属性,每一个都含有标识符、一组寄存器(包括程序计数器)和一组存储在结构中的属性。这个属性包括堆栈大小、调度参数以及其他线程需要的项目。
线程实现
主要有三种实现方式
- 在用户空间中实现线程;
- 在内核空间中实现线程;
- 在用户和内核空间中混合实现线程。
下面我们分开讨论一下
在用户空间中实现线程
第一种方法是把整个线程包放在用户空间中,内核对线程一无所知,它不知道线程的存在。所有的这类实现都有同样的通用结构
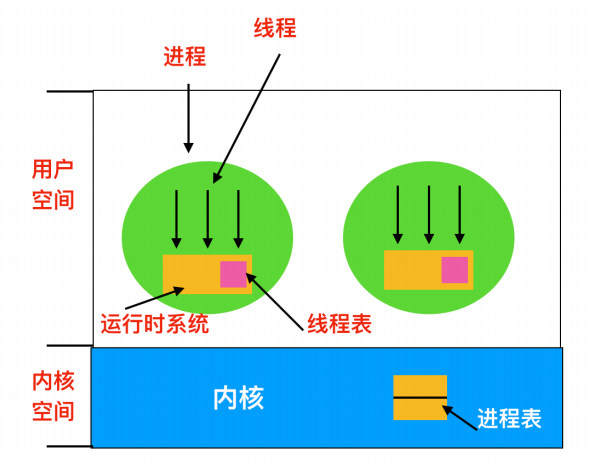
线程在运行时系统之上运行,运行时系统是管理线程过程的集合,包括前面提到的四个过程: pthread_create, pthread_exit, pthread_join 和 pthread_yield。
在内核中实现线程
当某个线程希望创建一个新线程或撤销一个已有线程时,它会进行一个系统调用,这个系统调用通过对线程表的更新来完成线程创建或销毁工作。

内核中的线程表持有每个线程的寄存器、状态和其他信息。这些信息和用户空间中的线程信息相同,但是位置却被放在了内核中而不是用户空间中。另外,内核还维护了一张进程表用来跟踪系统状态。
所有能够阻塞的调用都会通过系统调用的方式来实现,当一个线程阻塞时,内核可以进行选择,是运行在同一个进程中的另一个线程(如果有就绪线程的话)还是运行一个另一个进程中的线程。但是在用户实现中,运行时系统始终运行自己的线程,直到内核剥夺它的 CPU 时间片(或者没有可运行的线程存在了)为止。
混合实现
结合用户空间和内核空间的优点,设计人员采用了一种内核级线程的方式,然后将用户级线程与某些或者全部内核线程多路复用起来
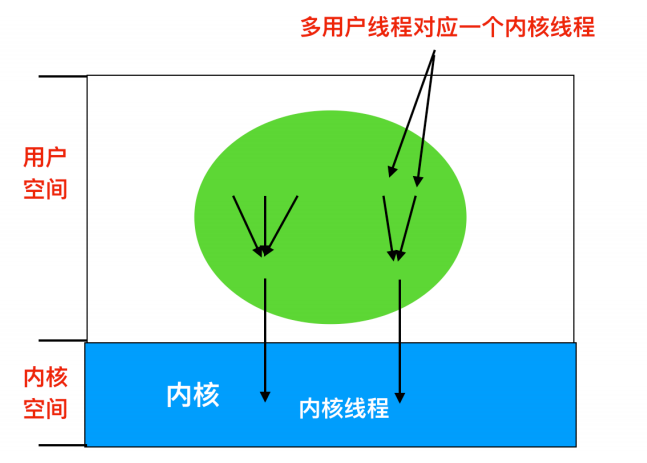
在这种模型中,编程人员可以自由控制用户线程和内核线程的数量,具有很大的灵活度。采用这种方法,内核只识别内核级线程,并对其进行调度。其中一些内核级线程会被多个用户级线程多路复用。
进程间通信
进程是需要频繁的和其他进程进行交流的。下面我们会一起讨论有关 进程间通信(Inter Process Communication, IPC) 的问题。大致来说,进程间的通信机制可以分为 6 种
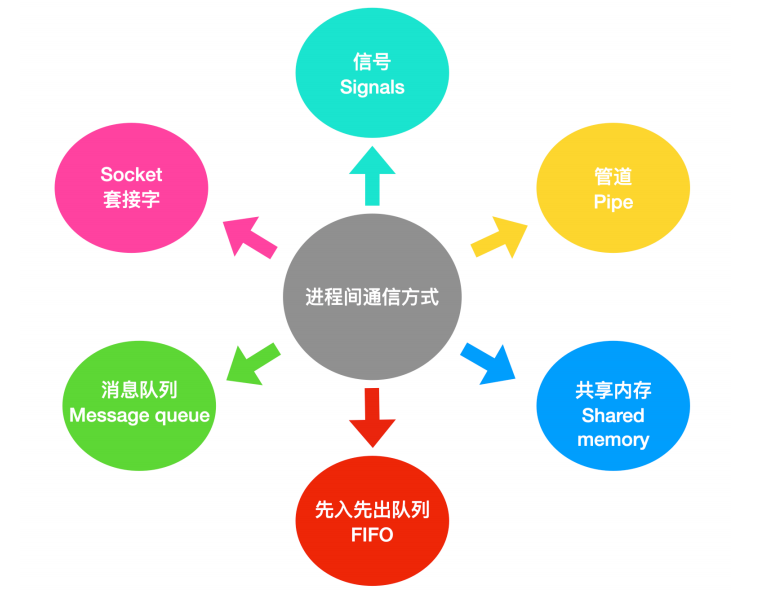
下面我们分别对其进行概述
信号 signal
信号是 UNIX 系统最先开始使用的进程间通信机制,因为 Linux 是继承于 UNIX 的,所以 Linux 也支持信号机制,通过向一个或多个进程发送异步事件信号来实现,信号可以从键盘或者访问不存在的位置等地方产生;信号通过 shell 将任务发送给子进程。
你可以在 Linux 系统上输入 kill -l 来列出系统使用的信号,下面是我提供的一些信号

进程可以选择忽略发送过来的信号,但是有两个是不能忽略的:SIGSTOP 和 SIGKILL 信号。SIGSTOP 信号会通知当前正在运行的进程执行关闭操作,SIGKILL 信号会通知当前进程应该被杀死。除此之外,进程可以选择它想要处理的信号,进程也可以选择阻止信号,如果不阻止,可以选择自行处理,也可以选择进行内核处理。如果选择交给内核进行处理,那么就执行默认处理。
操作系统会中断目标程序的进程来向其发送信号、在任何非原子指令中,执行都可以中断,如果进程已经注册了新号处理程序,那么就执行进程,如果没有注册,将采用默认处理的方式。
管道 pipe
Linux 系统中的进程可以通过建立管道 pipe 进行通信
在两个进程之间,可以建立一个通道,一个进程向这个通道里写入字节流,另一个进程从这个管道中读取字节流。管道是同步的,当进程尝试从空管道读取数据时,该进程会被阻塞,直到有可用数据为止。shell 中的管线 pipelines 就是用管道实现的,当 shell 发现输出
sort <f | head
它会创建两个进程,一个是 sort,一个是 head,sort,会在这两个应用程序之间建立一个管道使得 sort 进程的标准输出作为 head 程序的标准输入。sort 进程产生的输出就不用写到文件中了,如果管道满了系统会停止 sort 以等待 head 读出数据

管道实际上就是 |,两个应用程序不知道有管道的存在,一切都是由 shell 管理和控制的。
共享内存 shared memory
两个进程之间还可以通过共享内存进行进程间通信,其中两个或者多个进程可以访问公共内存空间。两个进程的共享工作是通过共享内存完成的,一个进程所作的修改可以对另一个进程可见(很像线程间的通信)。
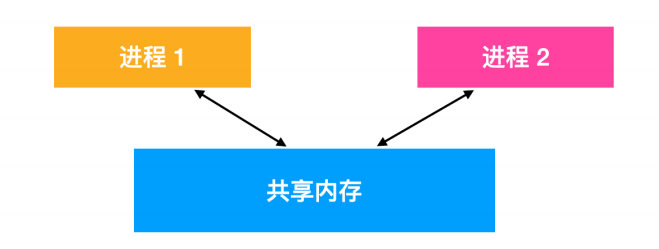
在使用共享内存前,需要经过一系列的调用流程,流程如下
- 创建共享内存段或者使用已创建的共享内存段
(shmget()) - 将进程附加到已经创建的内存段中
(shmat())
- 从已连接的共享内存段分离进程
(shmdt()) - 对共享内存段执行控制操作
(shmctl())
先入先出队列 FIFO
先入先出队列 FIFO 通常被称为 命名管道(Named Pipes),命名管道的工作方式与常规管道非常相似,但是确实有一些明显的区别。未命名的管道没有备份文件:操作系统负责维护内存中的缓冲区,用来将字节从写入器传输到读取器。一旦写入或者输出终止的话,缓冲区将被回收,传输的数据会丢失。相比之下,命名管道具有支持文件和独特 API ,命名管道在文件系统中作为设备的专用文件存在。当所有的进程通信完成后,命名管道将保留在文件系统中以备后用。命名管道具有严格的 FIFO 行为

写入的第一个字节是读取的第一个字节,写入的第二个字节是读取的第二个字节,依此类推。
消息队列 Message Queue
一听到消息队列这个名词你可能不知道是什么意思,消息队列是用来描述内核寻址空间内的内部链接列表。可以按几种不同的方式将消息按顺序发送到队列并从队列中检索消息。每个消息队列由 IPC 标识符唯一标识。消息队列有两种模式,一种是严格模式, 严格模式就像是 FIFO 先入先出队列似的,消息顺序发送,顺序读取。还有一种模式是 非严格模式,消息的顺序性不是非常重要。
套接字 Socket
还有一种管理两个进程间通信的是使用 socket,socket 提供端到端的双相通信。一个套接字可以与一个或多个进程关联。就像管道有命令管道和未命名管道一样,套接字也有两种模式,套接字一般用于两个进程之间的网络通信,网络套接字需要来自诸如TCP(传输控制协议)或较低级别UDP(用户数据报协议)等基础协议的支持。
套接字有以下几种分类
顺序包套接字(Sequential Packet Socket): 此类套接字为最大长度固定的数据报提供可靠的连接。此连接是双向的并且是顺序的。数据报套接字(Datagram Socket):数据包套接字支持双向数据流。数据包套接字接受消息的顺序与发送者可能不同。
流式套接字(Stream Socket):流套接字的工作方式类似于电话对话,提供双向可靠的数据流。原始套接字(Raw Socket): 可以使用原始套接字访问基础通信协议。
调度
当一个计算机是多道程序设计系统时,会频繁的有很多进程或者线程来同时竞争 CPU 时间片。当两个或两个以上的进程/线程处于就绪状态时,就会发生这种情况。如果只有一个 CPU 可用,那么必须选择接下来哪个进程/线程可以运行。操作系统中有一个叫做 调度程序(scheduler) 的角色存在,它就是做这件事儿的,该程序使用的算法叫做 调度算法(scheduling algorithm) 。
调度算法的分类
毫无疑问,不同的环境下需要不同的调度算法。之所以出现这种情况,是因为不同的应用程序和不同的操作系统有不同的目标。也就是说,在不同的系统中,调度程序的优化也是不同的。这里有必要划分出三种环境
批处理(Batch): 商业领域交互式(Interactive): 交互式用户环境
实时(Real time)
批处理中的调度
现在让我们把目光从一般性的调度转换为特定的调度算法。下面我们会探讨在批处理中的调度。
先来先服务
最简单的非抢占式调度算法的设计就是 先来先服务(first-come,first-serverd)。当第一个任务从外部进入系统时,将会立即启动并允许运行任意长的时间。它不会因为运行时间太长而中断。当其他作业进入时,它们排到就绪队列尾部。当正在运行的进程阻塞,处于等待队列的第一个进程就开始运行。当一个阻塞的进程重新处于就绪态时,它会像一个新到达的任务,会排在队列的末尾,即排在所有进程最后。

这个算法的强大之处在于易于理解和编程,在这个算法中,一个单链表记录了所有就绪进程。要选取一个进程运行,只要从该队列的头部移走一个进程即可;要添加一个新的作业或者阻塞一个进程,只要把这个作业或进程附加在队列的末尾即可。这是很简单的一种实现。
最短作业优先
批处理中,第二种调度算法是 最短作业优先(Shortest Job First),我们假设运行时间已知。例如,一家保险公司,因为每天要做类似的工作,所以人们可以相当精确地预测处理 1000 个索赔的一批作业需要多长时间。当输入队列中有若干个同等重要的作业被启动时,调度程序应使用最短优先作业算法
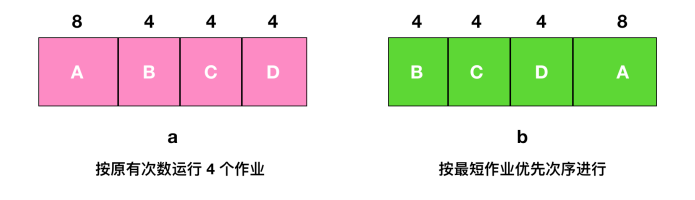
需要注意的是,在所有的进程都可以运行的情况下,最短作业优先的算法才是最优的。
最短剩余时间优先
最短作业优先的抢占式版本被称作为 最短剩余时间优先(Shortest Remaining Time Next) 算法。使用这个算法,调度程序总是选择剩余运行时间最短的那个进程运行。
交互式系统中的调度
交互式系统中在个人计算机、服务器和其他系统中都是很常用的,所以有必要来探讨一下交互式调度
轮询调度
一种最古老、最简单、最公平并且最广泛使用的算法就是 轮询算法(round-robin)。每个进程都会被分配一个时间段,称为时间片(quantum),在这个时间片内允许进程运行。如果时间片结束时进程还在运行的话,则抢占一个 CPU 并将其分配给另一个进程。如果进程在时间片结束前阻塞或结束,则 CPU 立即进行切换。轮询算法比较容易实现。调度程序所做的就是维护一个可运行进程的列表,就像下图中的 a,当一个进程用完时间片后就被移到队列的末尾,就像下图的 b。

优先级调度
轮询调度假设了所有的进程是同等重要的。但事实情况可能不是这样。例如,在一所大学中的等级制度,首先是院长,然后是教授、秘书、后勤人员,最后是学生。这种将外部情况考虑在内就实现了优先级调度(priority scheduling)

它的基本思想很明确,每个进程都被赋予一个优先级,优先级高的进程优先运行。
多级队列
最早使用优先级调度的系统是 CTSS(Compatible TimeSharing System)。CTSS 在每次切换前都需要将当前进程换出到磁盘,并从磁盘上读入一个新进程。为 CPU 密集型进程设置较长的时间片比频繁地分给他们很短的时间要更有效(减少交换次数)。另一方面,如前所述,长时间片的进程又会影响到响应时间,解决办法是设置优先级类。属于最高优先级的进程运行一个时间片,次高优先级进程运行 2 个时间片,再下面一级运行 4 个时间片,以此类推。当一个进程用完分配的时间片后,它被移到下一类。
最短进程优先
最短进程优先是根据进程过去的行为进行推测,并执行估计运行时间最短的那一个。假设每个终端上每条命令的预估运行时间为 T0,现在假设测量到其下一次运行时间为 T1,可以用两个值的加权来改进估计时间,即aT0+ (1- 1)T1。通过选择 a 的值,可以决定是尽快忘掉老的运行时间,还是在一段长时间内始终记住它们。当 a = 1/2 时,可以得到下面这个序列

可以看到,在三轮过后,T0 在新的估计值中所占比重下降至 1/8。
保证调度
一种完全不同的调度方法是对用户做出明确的性能保证。一种实际而且容易实现的保证是:若用户工作时有 n 个用户登录,则每个用户将获得 CPU 处理能力的 1/n。类似地,在一个有 n 个进程运行的单用户系统中,若所有的进程都等价,则每个进程将获得 1/n 的 CPU 时间。
彩票调度
对用户进行承诺并在随后兑现承诺是一件好事,不过很难实现。但是存在着一种简单的方式,有一种既可以给出预测结果而又有一种比较简单的实现方式的算法,就是 彩票调度(lottery scheduling)算法。
其基本思想是为进程提供各种系统资源(例如 CPU 时间)的彩票。当做出一个调度决策的时候,就随机抽出一张彩票,拥有彩票的进程将获得该资源。在应用到 CPU 调度时,系统可以每秒持有 50 次抽奖,每个中奖者将获得比如 20 毫秒的 CPU 时间作为奖励。
公平分享调度
到目前为止,我们假设被调度的都是各个进程自身,而不用考虑该进程的拥有者是谁。结果是,如果用户 1 启动了 9 个进程,而用户 2 启动了一个进程,使用轮转或相同优先级调度算法,那么用户 1 将得到 90 % 的 CPU 时间,而用户 2 将之得到 10 % 的 CPU 时间。
为了阻止这种情况的出现,一些系统在调度前会把进程的拥有者考虑在内。在这种模型下,每个用户都会分配一些CPU 时间,而调度程序会选择进程并强制执行。因此如果两个用户每个都会有 50% 的 CPU 时间片保证,那么无论一个用户有多少个进程,都将获得相同的 CPU 份额。

实时系统中的调度
实时系统(real-time) 是一个时间扮演了重要作用的系统。实时系统可以分为两类,硬实时(hard real time) 和 软实时(soft real time) 系统,前者意味着必须要满足绝对的截止时间;后者的含义是虽然不希望偶尔错失截止时间,但是可以容忍。
实时系统中的事件可以按照响应方式进一步分类为周期性(以规则的时间间隔发生)事件或 非周期性(发生时间不可预知)事件。一个系统可能要响应多个周期性事件流,根据每个事件处理所需的时间,可能甚至无法处理所有事件。例如,如果有 m 个周期事件,事件 i 以周期 Pi 发生,并需要 Ci 秒 CPU 时间处理一个事件,那么可以处理负载的条件是

只有满足这个条件的实时系统称为可调度的,这意味着它实际上能够被实现。一个不满足此检验标准的进程不能被调度,因为这些进程共同需要的 CPU 时间总和大于 CPU 能提供的时间。
下面我们来了解一下内存管理,你需要知道的知识点如下
地址空间
如果要使多个应用程序同时运行在内存中,必须要解决两个问题:保护和 重定位。第一种解决方式是用保护密钥标记内存块,并将执行过程的密钥与提取的每个存储字的密钥进行比较。这种方式只能解决第一种问题(破坏操作系统),但是不能解决多进程在内存中同时运行的问题。
还有一种更好的方式是创造一个存储器抽象:地址空间(the address space)。就像进程的概念创建了一种抽象的 CPU 来运行程序,地址空间也创建了一种抽象内存供程序使用。
基址寄存器和变址寄存器
最简单的办法是使用动态重定位(dynamic relocation)技术,它就是通过一种简单的方式将每个进程的地址空间映射到物理内存的不同区域。还有一种方式是使用基址寄存器和变址寄存器。
- 基址寄存器:存储数据内存的起始位置
- 变址寄存器:存储应用程序的长度。
每当进程引用内存以获取指令或读取、写入数据时,CPU 都会自动将基址值添加到进程生成的地址中,然后再将其发送到内存总线上。同时,它检查程序提供的地址是否大于或等于变址寄存器 中的值。如果程序提供的地址要超过变址寄存器的范围,那么会产生错误并中止访问。
交换技术
在程序运行过程中,经常会出现内存不足的问题。
针对上面内存不足的问题,提出了两种处理方式:最简单的一种方式就是交换(swapping)技术,即把一个进程完整的调入内存,然后再内存中运行一段时间,再把它放回磁盘。空闲进程会存储在磁盘中,所以这些进程在没有运行时不会占用太多内存。另外一种策略叫做虚拟内存(virtual memory),虚拟内存技术能够允许应用程序部分的运行在内存中。下面我们首先先探讨一下交换
交换过程
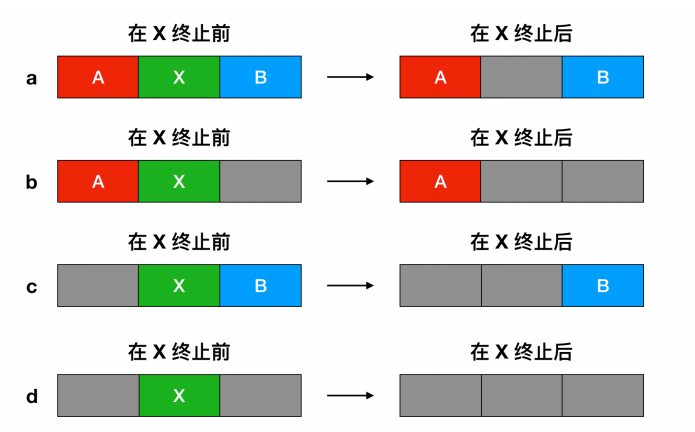
下面是一个交换过程
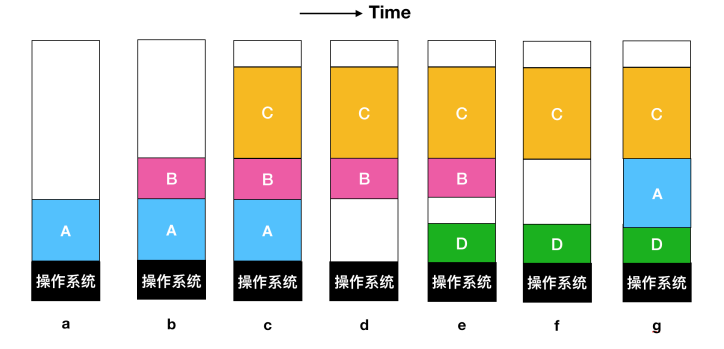
刚开始的时候,只有进程 A 在内存中,然后从创建进程 B 和进程 C 或者从磁盘中把它们换入内存,然后在图 d 中,A 被换出内存到磁盘中,最后 A 重新进来。因为图 g 中的进程 A 现在到了不同的位置,所以在装载过程中需要被重新定位,或者在交换程序时通过软件来执行;或者在程序执行期间通过硬件来重定位。基址寄存器和变址寄存器就适用于这种情况。
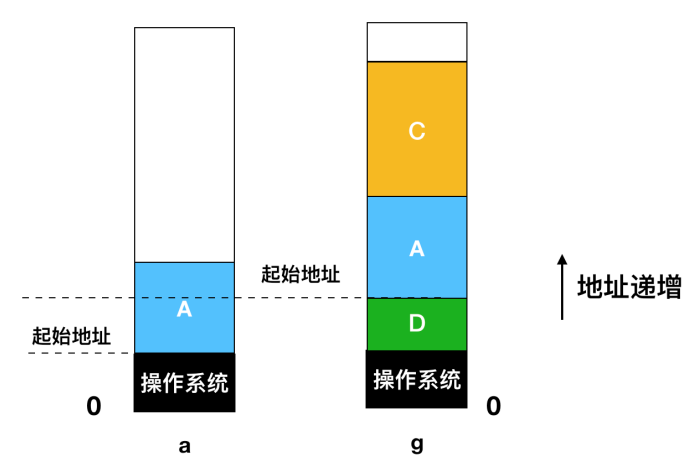
交换在内存创建了多个 空闲区(hole),内存会把所有的空闲区尽可能向下移动合并成为一个大的空闲区。这项技术称为内存紧缩(memory compaction)。但是这项技术通常不会使用,因为这项技术会消耗很多 CPU 时间。
空闲内存管理
在进行内存动态分配时,操作系统必须对其进行管理。大致上说,有两种监控内存使用的方式
位图(bitmap)空闲列表(free lists)
使用位图的存储管理
使用位图方法时,内存可能被划分为小到几个字或大到几千字节的分配单元。每个分配单元对应于位图中的一位,0 表示空闲, 1 表示占用(或者相反)。一块内存区域和其对应的位图如下
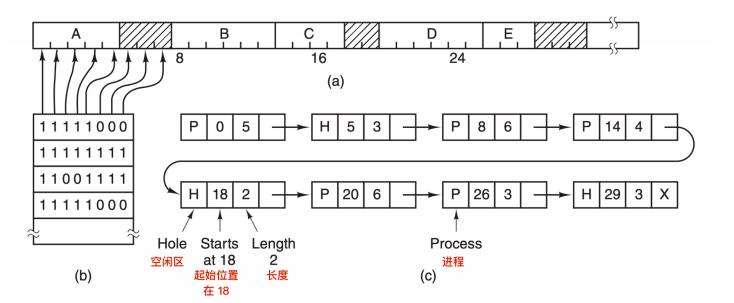
位图提供了一种简单的方法在固定大小的内存中跟踪内存的使用情况,因为位图的大小取决于内存和分配单元的大小。这种方法有一个问题是,当决定为把具有 k 个分配单元的进程放入内存时,内容管理器(memory manager) 必须搜索位图,在位图中找出能够运行 k 个连续 0 位的串。在位图中找出制定长度的连续 0 串是一个很耗时的操作,这是位图的缺点。(可以简单理解为在杂乱无章的数组中,找出具有一大长串空闲的数组单元)
使用链表进行管理
另一种记录内存使用情况的方法是,维护一个记录已分配内存段和空闲内存段的链表,段会包含进程或者是两个进程的空闲区域。可用上面的图 c 来表示内存的使用情况。链表中的每一项都可以代表一个 空闲区(H) 或者是进程(P)的起始标志,长度和下一个链表项的位置。
当按照地址顺序在链表中存放进程和空闲区时,有几种算法可以为创建的进程(或者从磁盘中换入的进程)分配内存。我们先假设内存管理器知道应该分配多少内存,最简单的算法是使用 首次适配(first fit)。内存管理器会沿着段列表进行扫描,直到找个一个足够大的空闲区为止。 除非空闲区大小和要分配的空间大小一样,否则将空闲区分为两部分,一部分供进程使用;一部分生成新的空闲区。首次适配算法是一种速度很快的算法,因为它会尽可能的搜索链表。
首次适配的一个小的变体是 下次适配(next fit)。它和首次匹配的工作方式相同,只有一个不同之处那就是下次适配在每次找到合适的空闲区时就会记录当时的位置,以便下次寻找空闲区时从上次结束的地方开始搜索,而不是像首次匹配算法那样每次都会从头开始搜索。
另外一个著名的并且广泛使用的算法是 最佳适配(best fit)。最佳适配会从头到尾寻找整个链表,找出能够容纳进程的最小空闲区。
虚拟内存
尽管基址寄存器和变址寄存器用来创建地址空间的抽象,但是这有一个其他的问题需要解决:管理软件的不断增大(managing bloatware)。虚拟内存的基本思想是,每个程序都有自己的地址空间,这个地址空间被划分为多个称为页面(page)的块。每一页都是连续的地址范围。这些页被映射到物理内存,但并不是所有的页都必须在内存中才能运行程序。当程序引用到一部分在物理内存中的地址空间时,硬件会立刻执行必要的映射。当程序引用到一部分不在物理内存中的地址空间时,由操作系统负责将缺失的部分装入物理内存并重新执行失败的指令。
分页
大部分使用虚拟内存的系统中都会使用一种 分页(paging) 技术。在任何一台计算机上,程序会引用使用一组内存地址。当程序执行
MOV REG,1000
这条指令时,它会把内存地址为 1000 的内存单元的内容复制到 REG 中(或者相反,这取决于计算机)。地址可以通过索引、基址寄存器、段寄存器或其他方式产生。
这些程序生成的地址被称为 虚拟地址(virtual addresses) 并形成虚拟地址空间(virtual address space),在没有虚拟内存的计算机上,系统直接将虚拟地址送到内存中线上,读写操作都使用同样地址的物理内存。在使用虚拟内存时,虚拟地址不会直接发送到内存总线上。相反,会使用 MMU(Memory Management Unit) 内存管理单元把虚拟地址映射为物理内存地址,像下图这样
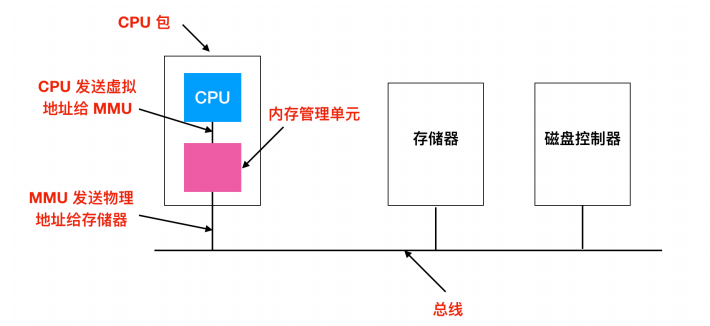
下面这幅图展示了这种映射是如何工作的
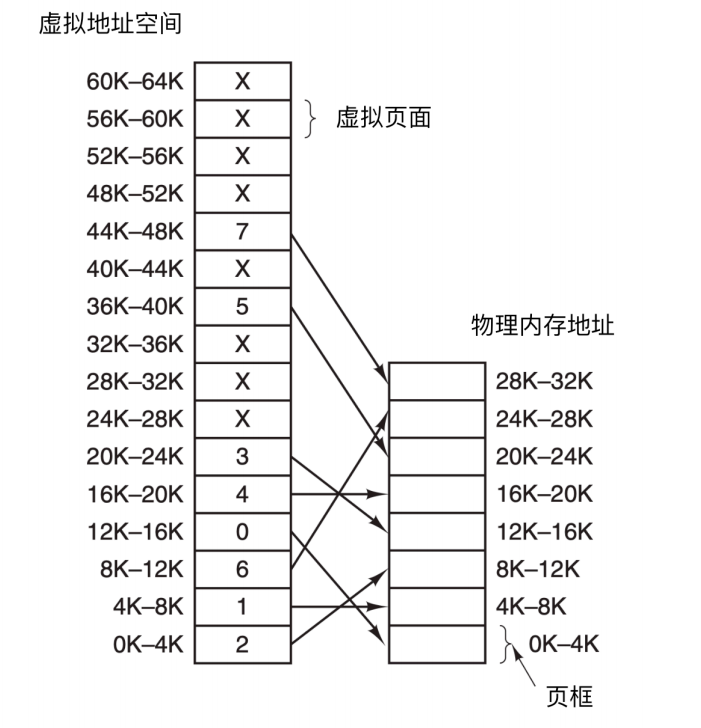
页表给出虚拟地址与物理内存地址之间的映射关系。每一页起始于 4096 的倍数位置,结束于 4095 的位置,所以 4K 到 8K 实际为 4096 - 8191 ,8K - 12K 就是 8192 - 12287
在这个例子中,我们可能有一个 16 位地址的计算机,地址从 0 - 64 K - 1,这些是虚拟地址。然而只有 32 KB 的物理地址。所以虽然可以编写 64 KB 的程序,但是程序无法全部调入内存运行,在磁盘上必须有一个最多 64 KB 的程序核心映像的完整副本,以保证程序片段在需要时被调入内存。
页表
虚拟页号可作为页表的索引用来找到虚拟页中的内容。由页表项可以找到页框号(如果有的话)。然后把页框号拼接到偏移量的高位端,以替换掉虚拟页号,形成物理地址。
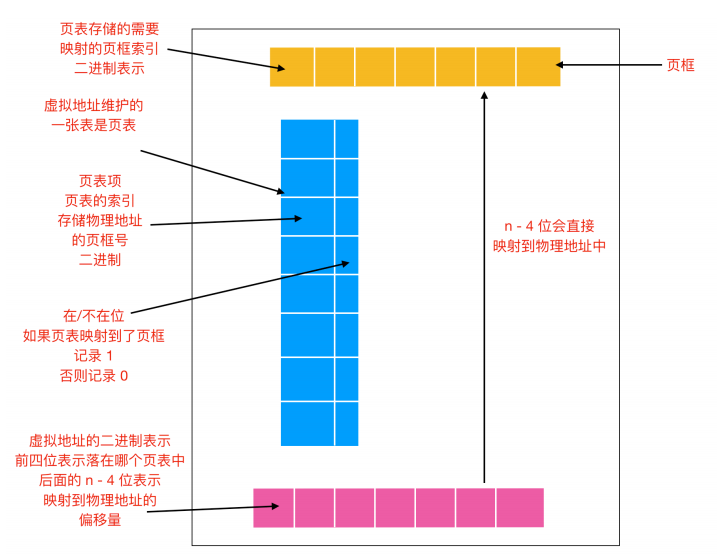
因此,页表的目的是把虚拟页映射到页框中。从数学上说,页表是一个函数,它的参数是虚拟页号,结果是物理页框号。

通过这个函数可以把虚拟地址中的虚拟页转换为页框,从而形成物理地址。
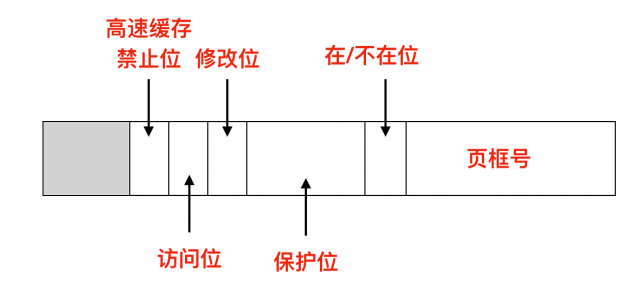
页表项的结构
下面我们探讨一下页表项的具体结构,上面你知道了页表项的大致构成,是由页框号和在/不在位构成的,现在我们来具体探讨一下页表项的构成

页表项的结构是与机器相关的,但是不同机器上的页表项大致相同。上面是一个页表项的构成,不同计算机的页表项可能不同,但是一般来说都是 32 位的。页表项中最重要的字段就是页框号(Page frame number)。毕竟,页表到页框最重要的一步操作就是要把此值映射过去。下一个比较重要的就是在/不在位,如果此位上的值是 1,那么页表项是有效的并且能够被使用。如果此值是 0 的话,则表示该页表项对应的虚拟页面不在内存中,访问该页面会引起一个缺页异常(page fault)。
保护位(Protection) 告诉我们哪一种访问是允许的,啥意思呢?最简单的表示形式是这个域只有一位,0 表示可读可写,1 表示的是只读。
修改位(Modified) 和 访问位(Referenced) 会跟踪页面的使用情况。当一个页面被写入时,硬件会自动的设置修改位。修改位在页面重新分配页框时很有用。如果一个页面已经被修改过(即它是 脏 的),则必须把它写回磁盘。如果一个页面没有被修改过(即它是 干净的),那么重新分配时这个页框会被直接丢弃,因为磁盘上的副本仍然是有效的。这个位有时也叫做 脏位(dirty bit),因为它反映了页面的状态。
访问位(Referenced) 在页面被访问时被设置,不管是读还是写。这个值能够帮助操作系统在发生缺页中断时选择要淘汰的页。不再使用的页要比正在使用的页更适合被淘汰。这个位在后面要讨论的页面置换算法中作用很大。
最后一位用于禁止该页面被高速缓存,这个功能对于映射到设备寄存器还是内存中起到了关键作用。通过这一位可以禁用高速缓存。具有独立的 I/O 空间而不是用内存映射 I/O 的机器来说,并不需要这一位。
页面置换算法
下面我们就来探讨一下有哪些页面置换算法。
最优页面置换算法
最优的页面置换算法的工作流程如下:在缺页中断发生时,这些页面之一将在下一条指令(包含该指令的页面)上被引用。其他页面则可能要到 10、100 或者 1000 条指令后才会被访问。每个页面都可以用在该页首次被访问前所要执行的指令数作为标记。
最优化的页面算法表明应该标记最大的页面。如果一个页面在 800 万条指令内不会被使用,另外一个页面在 600 万条指令内不会被使用,则置换前一个页面,从而把需要调入这个页面而发生的缺页中断推迟。计算机也像人类一样,会把不愿意做的事情尽可能的往后拖。
这个算法最大的问题时无法实现。当缺页中断发生时,操作系统无法知道各个页面的下一次将在什么时候被访问。这种算法在实际过程中根本不会使用。
最近未使用页面置换算法
为了能够让操作系统收集页面使用信息,大部分使用虚拟地址的计算机都有两个状态位,R 和 M,来和每个页面进行关联。每当引用页面(读入或写入)时都设置 R,写入(即修改)页面时设置 M,这些位包含在每个页表项中,就像下面所示
因为每次访问时都会更新这些位,因此由硬件来设置它们非常重要。一旦某个位被设置为 1,就会一直保持 1 直到操作系统下次来修改此位。
如果硬件没有这些位,那么可以使用操作系统的缺页中断和时钟中断机制来进行模拟。当启动一个进程时,将其所有的页面都标记为不在内存;一旦访问任何一个页面就会引发一次缺页中断,此时操作系统就可以设置 R 位(在它的内部表中),修改页表项使其指向正确的页面,并设置为 READ ONLY 模式,然后重新启动引起缺页中断的指令。如果页面随后被修改,就会发生另一个缺页异常。从而允许操作系统设置 M 位并把页面的模式设置为 READ/WRITE。
可以用 R 位和 M 位来构造一个简单的页面置换算法:当启动一个进程时,操作系统将其所有页面的两个位都设置为 0。R 位定期的被清零(在每个时钟中断)。用来将最近未引用的页面和已引用的页面分开。
当出现缺页中断后,操作系统会检查所有的页面,并根据它们的 R 位和 M 位将当前值分为四类:
- 第 0 类:没有引用 R,没有修改 M
- 第 1 类:没有引用 R,已修改 M
- 第 2 类:引用 R ,没有修改 M
- 第 3 类:已被访问 R,已被修改 M
尽管看起来好像无法实现第一类页面,但是当第三类页面的 R 位被时钟中断清除时,它们就会发生。时钟中断不会清除 M 位,因为需要这个信息才能知道是否写回磁盘中。清除 R 但不清除 M 会导致出现一类页面。
NRU(Not Recently Used) 算法从编号最小的非空类中随机删除一个页面。此算法隐含的思想是,在一个时钟内(约 20 ms)淘汰一个已修改但是没有被访问的页面要比一个大量引用的未修改页面好,NRU 的主要优点是易于理解并且能够有效的实现。
先进先出页面置换算法
另一种开销较小的方式是使用 FIFO(First-In,First-Out) 算法,这种类型的数据结构也适用在页面置换算法中。由操作系统维护一个所有在当前内存中的页面的链表,最早进入的放在表头,最新进入的页面放在表尾。在发生缺页异常时,会把头部的页移除并且把新的页添加到表尾。
第二次机会页面置换算法
我们上面学到的 FIFO 链表页面有个缺陷,那就是出链和入链并不会进行 check 检查,这样就会容易把经常使用的页面置换出去,为了避免这一问题,我们对该算法做一个简单的修改:我们检查最老页面的 R 位,如果是 0 ,那么这个页面就是最老的而且没有被使用,那么这个页面就会被立刻换出。如果 R 位是 1,那么就清除此位,此页面会被放在链表的尾部,修改它的装入时间就像刚放进来的一样。然后继续搜索。
这种算法叫做 第二次机会(second chance)算法,就像下面这样,我们看到页面 A 到 H 保留在链表中,并按到达内存的时间排序。
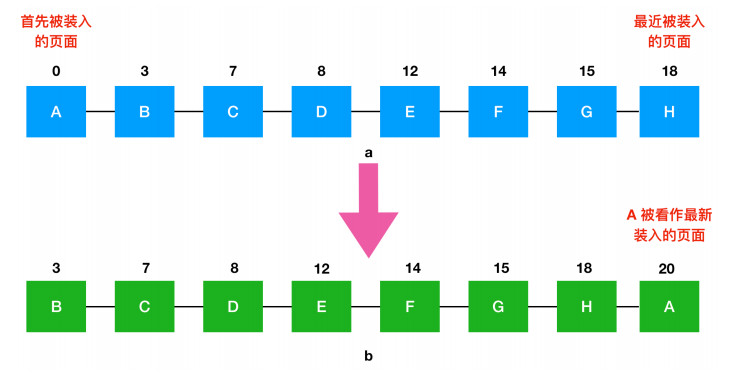
a)按照先进先出的方法排列的页面;b)在时刻 20 处发生缺页异常中断并且 A 的 R 位已经设置时的页面链表。
假设缺页异常发生在时刻 20 处,这时最老的页面是 A ,它是在 0 时刻到达的。如果 A 的 R 位是 0,那么它将被淘汰出内存,或者把它写回磁盘(如果它已经被修改过),或者只是简单的放弃(如果它是未被修改过)。另一方面,如果它的 R 位已经设置了,则将 A 放到链表的尾部并且重新设置装入时间为当前时刻(20 处),然后清除 R 位。然后从 B 页面开始继续搜索合适的页面。
寻找第二次机会的是在最近的时钟间隔中未被访问过的页面。如果所有的页面都被访问过,该算法就会被简化为单纯的 FIFO 算法。具体来说,假设图 a 中所有页面都设置了 R 位。操作系统将页面依次移到链表末尾,每次都在添加到末尾时清除 R 位。最后,算法又会回到页面 A,此时的 R 位已经被清除,那么页面 A 就会被执行出链处理,因此算法能够正常结束。
时钟页面置换算法
一种比较好的方式是把所有的页面都保存在一个类似钟面的环形链表中,一个表针指向最老的页面。如下图所示
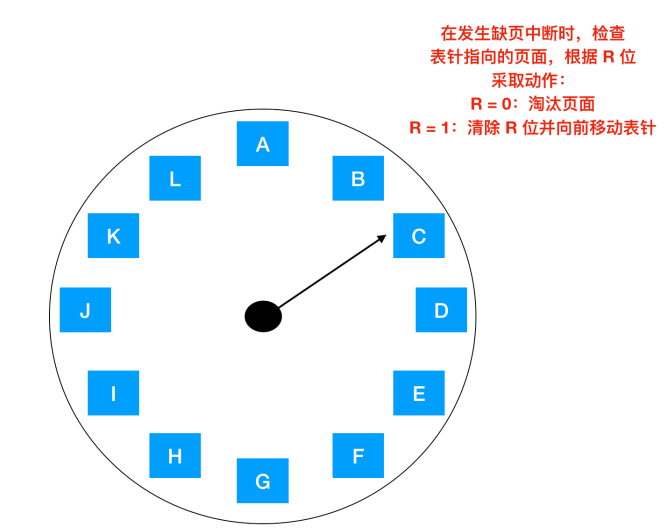
当缺页错误出现时,算法首先检查表针指向的页面,如果它的 R 位是 0 就淘汰该页面,并把新的页面插入到这个位置,然后把表针向前移动一位;如果 R 位是 1 就清除 R 位并把表针前移一个位置。重复这个过程直到找到了一个 R 位为 0 的页面位置。了解这个算法的工作方式,就明白为什么它被称为 时钟(clokc)算法了。
最近最少使用页面置换算法
在前面几条指令中频繁使用的页面和可能在后面的几条指令中被使用。反过来说,已经很久没有使用的页面有可能在未来一段时间内仍不会被使用。这个思想揭示了一个可以实现的算法:在缺页中断时,置换未使用时间最长的页面。这个策略称为 LRU(Least Recently Used) ,最近最少使用页面置换算法。
虽然 LRU 在理论上是可以实现的,但是从长远看来代价比较高。为了完全实现 LRU,会在内存中维护一个所有页面的链表,最频繁使用的页位于表头,最近最少使用的页位于表尾。困难的是在每次内存引用时更新整个链表。在链表中找到一个页面,删除它,然后把它移动到表头是一个非常耗时的操作,即使使用硬件来实现也是一样的费时。
用软件模拟 LRU
尽管上面的 LRU 算法在原则上是可以实现的,但是很少有机器能够拥有那些特殊的硬件。上面是硬件的实现方式,那么现在考虑要用软件来实现 LRU 。一种可以实现的方案是 NFU(Not Frequently Used,最不常用)算法。它需要一个软件计数器来和每个页面关联,初始化的时候是 0 。在每个时钟中断时,操作系统会浏览内存中的所有页,会将每个页面的 R 位(0 或 1)加到它的计数器上。这个计数器大体上跟踪了各个页面访问的频繁程度。当缺页异常出现时,则置换计数器值最小的页面。
只需要对 NFU 做一个简单的修改就可以让它模拟 LRU,这个修改有两个步骤
- 首先,在 R 位被添加进来之前先把计数器右移一位;
- 第二步,R 位被添加到最左边的位而不是最右边的位。
修改以后的算法称为 老化(aging) 算法,下图解释了老化算法是如何工作的。
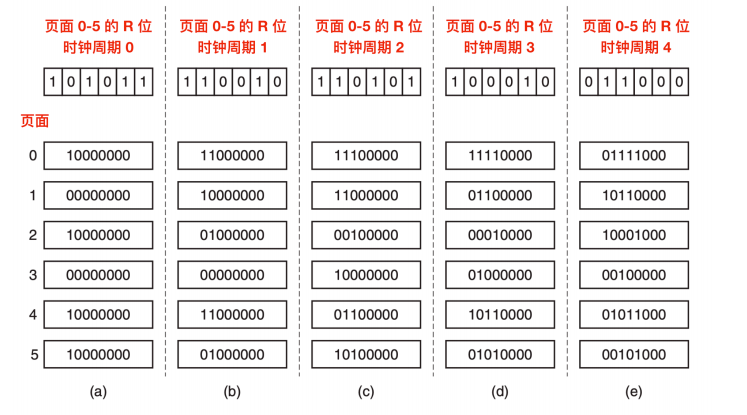
我们假设在第一个时钟周期内页面 0 - 5 的 R 位依次是 1,0,1,0,1,1,(也就是页面 0 是 1,页面 1 是 0,页面 2 是 1 这样类推)。也就是说,在 0 个时钟周期到 1 个时钟周期之间,0,2,4,5 都被引用了,从而把它们的 R 位设置为 1,剩下的设置为 0 。在相关的六个计数器被右移之后 R 位被添加到 左侧 ,就像上图中的 a。剩下的四列显示了接下来的四个时钟周期内的六个计数器变化。
CPU正在以某个频率前进,该频率的周期称为时钟滴答或时钟周期。一个 100Mhz 的处理器每秒将接收100,000,000个时钟滴答。
当缺页异常出现时,将置换(就是移除)计数器值最小的页面。如果一个页面在前面 4 个时钟周期内都没有被访问过,那么它的计数器应该会有四个连续的 0 ,因此它的值肯定要比前面 3 个时钟周期内都没有被访问过的页面的计数器小。
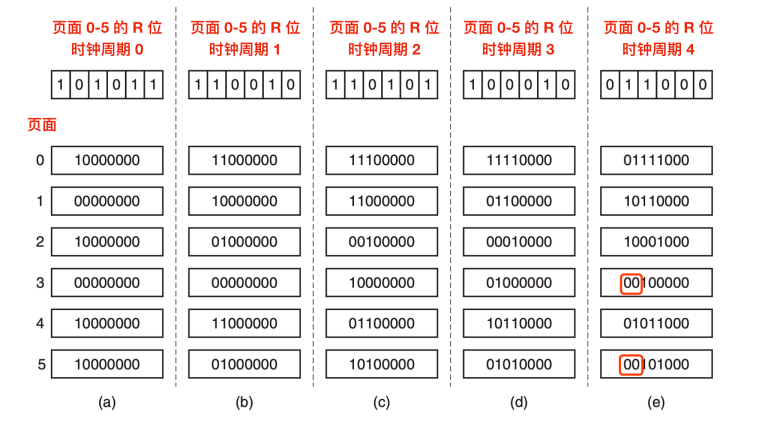
这个算法与 LRU 算法有两个重要的区别:看一下上图中的 e,第三列和第五列
工作集时钟页面置换算法
当缺页异常发生后,需要扫描整个页表才能确定被淘汰的页面,因此基本工作集算法还是比较浪费时间的。一个对基本工作集算法的提升是基于时钟算法但是却使用工作集的信息,这种算法称为WSClock(工作集时钟)。由于它的实现简单并且具有高性能,因此在实践中被广泛应用。
与时钟算法一样,所需的数据结构是一个以页框为元素的循环列表,就像下面这样
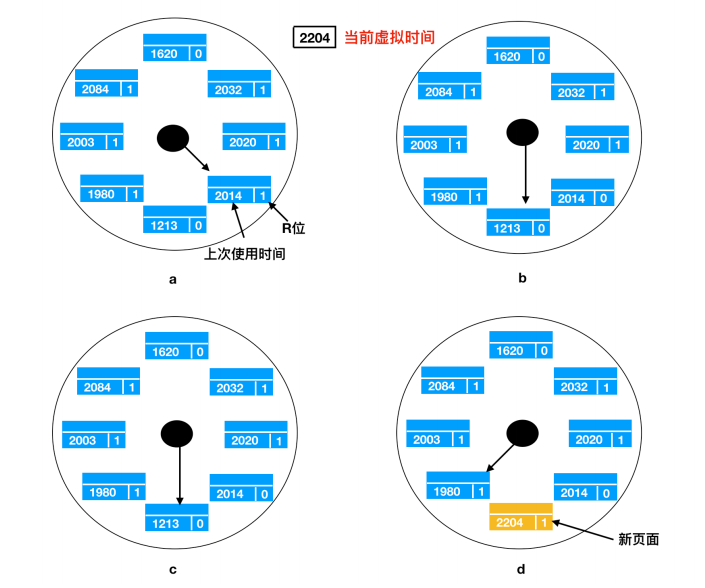
工作集时钟页面置换算法的操作:a) 和 b) 给出 R = 1 时所发生的情形;c) 和 d) 给出 R = 0 的例子
最初的时候,该表是空的。当装入第一个页面后,把它加载到该表中。随着更多的页面的加入,它们形成一个环形结构。每个表项包含来自基本工作集算法的上次使用时间,以及 R 位(已标明)和 M 位(未标明)。
与时钟算法一样,在每个缺页异常时,首先检查指针指向的页面。如果 R 位被是设置为 1,该页面在当前时钟周期内就被使用过,那么该页面就不适合被淘汰。然后把该页面的 R 位置为 0,指针指向下一个页面,并重复该算法。该事件序列化后的状态参见图 b。
现在考虑指针指向的页面 R = 0 时会发生什么,参见图 c,如果页面的使用期限大于 t 并且页面为被访问过,那么这个页面就不会在工作集中,并且在磁盘上会有一个此页面的副本。申请重新调入一个新的页面,并把新的页面放在其中,如图 d 所示。另一方面,如果页面被修改过,就不能重新申请页面,因为这个页面在磁盘上没有有效的副本。为了避免由于调度写磁盘操作引起的进程切换,指针继续向前走,算法继续对下一个页面进行操作。毕竟,有可能存在一个老的,没有被修改过的页面可以立即使用。
原则上来说,所有的页面都有可能因为磁盘I/O 在某个时钟周期内被调度。为了降低磁盘阻塞,需要设置一个限制,即最大只允许写回 n 个页面。一旦达到该限制,就不允许调度新的写操作。
那么就有个问题,指针会绕一圈回到原点的,如果回到原点,它的起始点会发生什么?这里有两种情况:
- 至少调度了一次写操作
- 没有调度过写操作
在第一种情况中,指针仅仅是不停的移动,寻找一个未被修改过的页面。由于已经调度了一个或者多个写操作,最终会有某个写操作完成,它的页面会被标记为未修改。置换遇到的第一个未被修改过的页面,这个页面不一定是第一个被调度写操作的页面,因为硬盘驱动程序为了优化性能可能会把写操作重排序。
对于第二种情况,所有的页面都在工作集中,否则将至少调度了一个写操作。由于缺乏额外的信息,最简单的方法就是置换一个未被修改的页面来使用,扫描中需要记录未被修改的页面的位置,如果不存在未被修改的页面,就选定当前页面并把它写回磁盘。
页面置换算法小结
我们到现在已经研究了各种页面置换算法,现在我们来一个简单的总结,算法的总结归纳如下
算法 | 注释 |
最优算法 | 不可实现,但可以用作基准 |
NRU(最近未使用) 算法 | 和 LRU 算法很相似 |
FIFO(先进先出) 算法 | 有可能会抛弃重要的页面 |
第二次机会算法 | 比 FIFO 有较大的改善 |
时钟算法 | 实际使用 |
LRU(最近最少)算法 | 比较优秀,但是很难实现 |
NFU(最不经常食用)算法 | 和 LRU 很类似 |
老化算法 | 近似 LRU 的高效算法 |
工作集算法 | 实施起来开销很大 |
工作集时钟算法 | 比较有效的算法 |
最优算法在当前页面中置换最后要访问的页面。不幸的是,没有办法来判定哪个页面是最后一个要访问的,因此实际上该算法不能使用。然而,它可以作为衡量其他算法的标准。NRU算法根据 R 位和 M 位的状态将页面氛围四类。从编号最小的类别中随机选择一个页面。NRU 算法易于实现,但是性能不是很好。存在更好的算法。
FIFO会跟踪页面加载进入内存中的顺序,并把页面放入一个链表中。有可能删除存在时间最长但是还在使用的页面,因此这个算法也不是一个很好的选择。第二次机会算法是对 FIFO 的一个修改,它会在删除页面之前检查这个页面是否仍在使用。如果页面正在使用,就会进行保留。这个改进大大提高了性能。
时钟算法是第二次机会算法的另外一种实现形式,时钟算法和第二次算法的性能差不多,但是会花费更少的时间来执行算法。LRU算法是一个非常优秀的算法,但是没有特殊的硬件(TLB)很难实现。如果没有硬件,就不能使用 LRU 算法。
NFU算法是一种近似于 LRU 的算法,它的性能不是非常好。老化算法是一种更接近 LRU 算法的实现,并且可以更好的实现,因此是一个很好的选择
- 最后两种算法都使用了工作集算法。工作集算法提供了合理的性能开销,但是它的实现比较复杂。
WSClock是另外一种变体,它不仅能够提供良好的性能,而且可以高效地实现。
总之,最好的算法是老化算法和WSClock算法。他们分别是基于 LRU 和工作集算法。他们都具有良好的性能并且能够被有效的实现。还存在其他一些好的算法,但实际上这两个可能是最重要的。
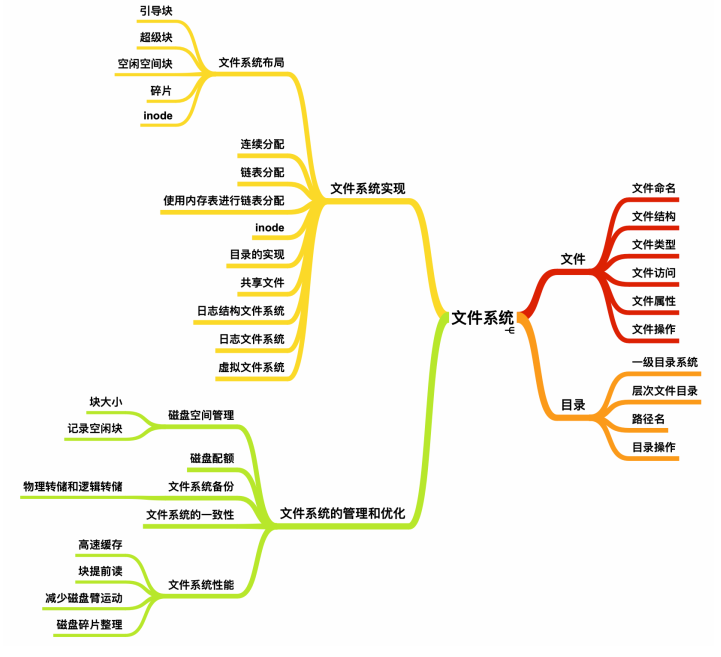
下面来聊一聊文件系统,你需要知道下面这些知识点
文件
文件命名
文件是一种抽象机制,它提供了一种方式用来存储信息以及在后面进行读取。可能任何一种机制最重要的特性就是管理对象的命名方式。在创建一个文件后,它会给文件一个命名。当进程终止时,文件会继续存在,并且其他进程可以使用名称访问该文件。
文件命名规则对于不同的操作系统来说是不一样的,但是所有现代操作系统都允许使用 1 - 8 个字母的字符串作为合法文件名。
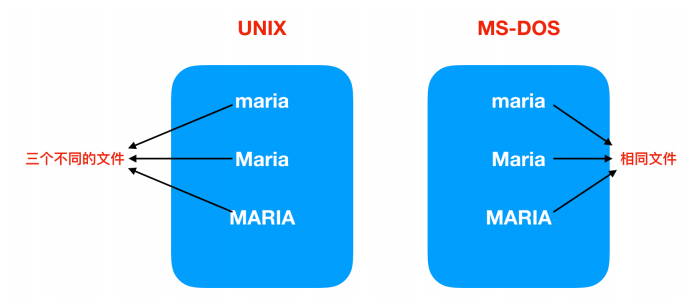
某些文件区分大小写字母,而大多数则不区分。UNIX 属于第一类;历史悠久的 MS-DOS 属于第二类(顺便说一句,尽管 MS-DOS 历史悠久,但 MS-DOS 仍在嵌入式系统中非常广泛地使用,因此它绝不是过时的);因此,UNIX 系统会有三种不同的命名文件:maria、Maria、MARIA 。在 MS-DOS ,所有这些命名都属于相同的文件。
许多操作系统支持两部分的文件名,它们之间用 . 分隔开,比如文件名 prog.c。原点后面的文件称为 文件扩展名(file extension) ,文件扩展名通常表示文件的一些信息。一些常用的文件扩展名以及含义如下图所示
扩展名 | 含义 |
bak | 备份文件 |
c | c 源程序文件 |
gif | 符合图形交换格式的图像文件 |
hlp | 帮助文件 |
html | WWW 超文本标记语言文档 |
jpg | 符合 JPEG 编码标准的静态图片 |
mp3 | 符合 MP3 音频编码格式的音乐文件 |
mpg | 符合 MPEG 编码标准的电影 |
o | 目标文件(编译器输出格式,尚未链接) |
pdf 格式的文件 | |
ps | PostScript 文件 |
tex | 为 TEX 格式化程序准备的输入文件 |
txt | 文本文件 |
zip | 压缩文件 |
在 UNIX 系统中,文件扩展名只是一种约定,操作系统并不强制采用。
文件结构
文件的构造有多种方式。下图列出了常用的三种构造方式
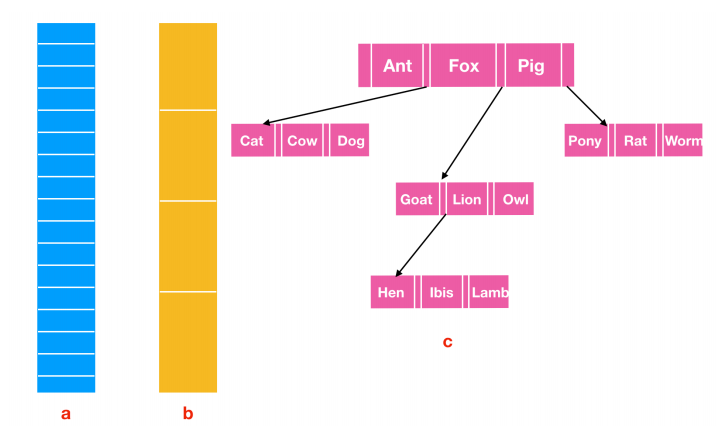
三种不同的文件。 a) 字节序列 。b) 记录序列。c) 树
上图中的 a 是一种无结构的字节序列,操作系统不关心序列的内容是什么,操作系统能看到的就是字节(bytes)。其文件内容的任何含义只在用户程序中进行解释。UNIX 和 Windows 都采用这种办法。
图 b 表示在文件结构上的第一部改进。在这个模型中,文件是具有固定长度记录的序列,每个记录都有其内部结构。 把文件作为记录序列的核心思想是:读操作返回一个记录,而写操作重写或者追加一个记录。第三种文件结构如上图 c 所示。在这种组织结构中,文件由一颗记录树构成,记录树的长度不一定相同,每个记录树都在记录中的固定位置包含一个key 字段。这棵树按 key 进行排序,从而可以对特定的 key 进行快速查找。
文件类型
很多操作系统支持多种文件类型。例如,UNIX(同样包括 OS X)和 Windows 都具有常规的文件和目录。除此之外,UNIX 还具有字符特殊文件(character special file) 和 块特殊文件(block special file)。常规文件(Regular files) 是包含有用户信息的文件。用户一般使用的文件大都是常规文件,常规文件一般包括 可执行文件、文本文件、图像文件,从常规文件读取数据或将数据写入时,内核会根据文件系统的规则执行操作,是写入可能被延迟,记录日志或者接受其他操作。
文件访问
早期的操作系统只有一种访问方式:序列访问(sequential access)。在这些系统中,进程可以按照顺序读取所有的字节或文件中的记录,但是不能跳过并乱序执行它们。顺序访问文件是可以返回到起点的,需要时可以多次读取该文件。当存储介质是磁带而不是磁盘时,顺序访问文件很方便。
在使用磁盘来存储文件时,可以不按照顺序读取文件中的字节或者记录,或者按照关键字而不是位置来访问记录。这种能够以任意次序进行读取的称为随机访问文件(random access file)。许多应用程序都需要这种方式。
随机访问文件对许多应用程序来说都必不可少,例如,数据库系统。如果乘客打电话预定某航班机票,订票程序必须能够直接访问航班记录,而不必先读取其他航班的成千上万条记录。
有两种方法可以指示从何处开始读取文件。第一种方法是直接使用 read 从头开始读取。另一种是用一个特殊的 seek 操作设置当前位置,在 seek 操作后,从这个当前位置顺序地开始读文件。UNIX 和 Windows 使用的是后面一种方式。
文件属性
文件包括文件名和数据。除此之外,所有的操作系统还会保存其他与文件相关的信息,如文件创建的日期和时间、文件大小。我们可以称这些为文件的属性(attributes)。有些人也喜欢把它们称作 元数据(metadata)。文件的属性在不同的系统中差别很大。文件的属性只有两种状态:设置(set) 和 清除(clear)。
文件操作
使用文件的目的是用来存储信息并方便以后的检索。对于存储和检索,不同的系统提供了不同的操作。以下是与文件有关的最常用的一些系统调用:
Create,创建不包含任何数据的文件。调用的目的是表示文件即将建立,并对文件设置一些属性。Delete,当文件不再需要,必须删除它以释放内存空间。为此总会有一个系统调用来删除文件。
Open,在使用文件之前,必须先打开文件。这个调用的目的是允许系统将属性和磁盘地址列表保存到主存中,用来以后的快速访问。Close,当所有进程完成时,属性和磁盘地址不再需要,因此应关闭文件以释放表空间。很多系统限制进程打开文件的个数,以此达到鼓励用户关闭不再使用的文件。磁盘以块为单位写入,关闭文件时会强制写入最后一块,即使这个块空间内部还不满。
Read,数据从文件中读取。通常情况下,读取的数据来自文件的当前位置。调用者必须指定需要读取多少数据,并且提供存放这些数据的缓冲区。Write,向文件写数据,写操作一般也是从文件的当前位置开始进行。如果当前位置是文件的末尾,则会直接追加进行写入。如果当前位置在文件中,则现有数据被覆盖,并且永远消失。
append,使用 append 只能向文件末尾添加数据。seek,对于随机访问的文件,要指定从何处开始获取数据。通常的方法是用 seek 系统调用把当前位置指针指向文件中的特定位置。seek 调用结束后,就可以从指定位置开始读写数据了。
get attributes,进程运行时通常需要读取文件属性。set attributes,用户可以自己设置一些文件属性,甚至是在文件创建之后,实现该功能的是 set attributes 系统调用。
rename,用户可以自己更改已有文件的名字,rename 系统调用用于这一目的。
目录
文件系统通常提供目录(directories) 或者 文件夹(folders) 用于记录文件的位置,在很多系统中目录本身也是文件,下面我们会讨论关于文件,他们的组织形式、属性和可以对文件进行的操作。
一级目录系统
目录系统最简单的形式是有一个能够包含所有文件的目录。这种目录被称为根目录(root directory),由于根目录的唯一性,所以其名称并不重要。在最早期的个人计算机中,这种系统很常见,部分原因是因为只有一个用户。下面是一个单层目录系统的例子

含有四个文件的单层目录系统
该目录中有四个文件。这种设计的优点在于简单,并且能够快速定位文件,毕竟只有一个地方可以检索。这种目录组织形式现在一般用于简单的嵌入式设备(如数码相机和某些便携式音乐播放器)上使用。
层次目录系统
对于简单的应用而言,一般都用单层目录方式,但是这种组织形式并不适合于现代计算机,因为现代计算机含有成千上万个文件和文件夹。如果都放在根目录下,查找起来会非常困难。为了解决这一问题,出现了层次目录系统(Hierarchical Directory Systems),也称为目录树。通过这种方式,可以用很多目录把文件进行分组。进而,如果多个用户共享同一个文件服务器,比如公司的网络系统,每个用户可以为自己的目录树拥有自己的私人根目录。这种方式的组织结构如下
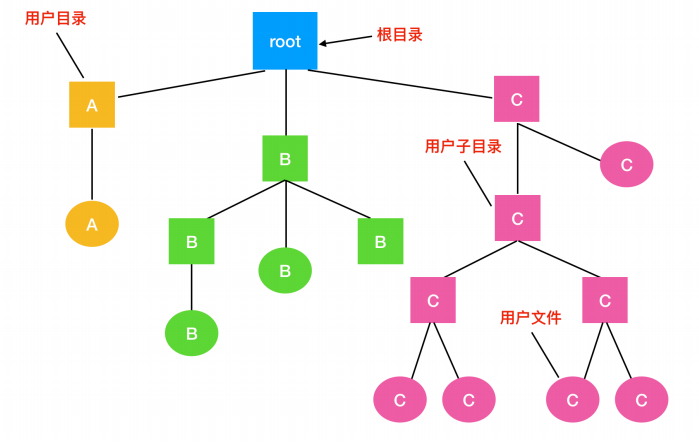
根目录含有目录 A、B 和 C ,分别属于不同的用户,其中两个用户个字创建了子目录。用户可以创建任意数量的子目录,现代文件系统都是按照这种方式组织的。
路径名
当目录树组织文件系统时,需要有某种方法指明文件名。常用的方法有两种,第一种方式是每个文件都会用一个绝对路径名(absolute path name),它由根目录到文件的路径组成。
另外一种指定文件名的方法是 相对路径名(relative path name)。它常常和 工作目录(working directory) (也称作 当前目录(current directory))一起使用。用户可以指定一个目录作为当前工作目录。例如,如果当前目录是 /usr/ast,那么绝对路径 /usr/ast/mailbox可以直接使用 mailbox 来引用。
目录操作
不同文件中管理目录的系统调用的差别比管理文件的系统调用差别大。为了了解这些系统调用有哪些以及它们怎样工作,下面给出一个例子(取自 UNIX)。
Create,创建目录,除了目录项.和..外,目录内容为空。Delete,删除目录,只有空目录可以删除。只包含.和..的目录被认为是空目录,这两个目录项通常不能删除
opendir,目录内容可被读取。例如,未列出目录中的全部文件,程序必须先打开该目录,然后读其中全部文件的文件名。与打开和读文件相同,在读目录前,必须先打开文件。closedir,读目录结束后,应该关闭目录用于释放内部表空间。
readdir,系统调用 readdir 返回打开目录的下一个目录项。以前也采用 read 系统调用来读取目录,但是这种方法有一个缺点:程序员必须了解和处理目录的内部结构。相反,不论采用哪一种目录结构,readdir 总是以标准格式返回一个目录项。rename,在很多方面目录和文件都相似。文件可以更换名称,目录也可以。
link,链接技术允许在多个目录中出现同一个文件。这个系统调用指定一个存在的文件和一个路径名,并建立从该文件到路径所指名字的链接。这样,可以在多个目录中出现同一个文件。有时也被称为硬链接(hard link)。unlink,删除目录项。如果被解除链接的文件只出现在一个目录中,则将它从文件中删除。如果它出现在多个目录中,则只删除指定路径名的链接,依然保留其他路径名的链接。在 UNIX 中,用于删除文件的系统调用就是 unlink。
文件系统的实现
文件系统布局
文件系统存储在磁盘中。大部分的磁盘能够划分出一到多个分区,叫做磁盘分区(disk partitioning) 或者是磁盘分片(disk slicing)。每个分区都有独立的文件系统,每块分区的文件系统可以不同。磁盘的 0 号分区称为 主引导记录(Master Boot Record, MBR),用来引导(boot) 计算机。在 MBR 的结尾是分区表(partition table)。每个分区表给出每个分区由开始到结束的地址。
当计算机开始引 boot 时,BIOS 读入并执行 MBR。
引导块
MBR 做的第一件事就是确定活动分区,读入它的第一个块,称为引导块(boot block) 并执行。引导块中的程序将加载分区中的操作系统。为了一致性,每个分区都会从引导块开始,即使引导块不包含操作系统。引导块占据文件系统的前 4096 个字节,从磁盘上的字节偏移量 0 开始。引导块可用于启动操作系统。
除了从引导块开始之外,磁盘分区的布局是随着文件系统的不同而变化的。通常文件系统会包含一些属性,如下

文件系统布局
超级块
紧跟在引导块后面的是 超级块(Superblock),超级块 的大小为 4096 字节,从磁盘上的字节偏移 4096 开始。超级块包含文件系统的所有关键参数
- 文件系统的大小
- 文件系统中的数据块数
- 指示文件系统状态的标志
- 分配组大小
在计算机启动或者文件系统首次使用时,超级块会被读入内存。
空闲空间块
接着是文件系统中空闲块的信息,例如,可以用位图或者指针列表的形式给出。
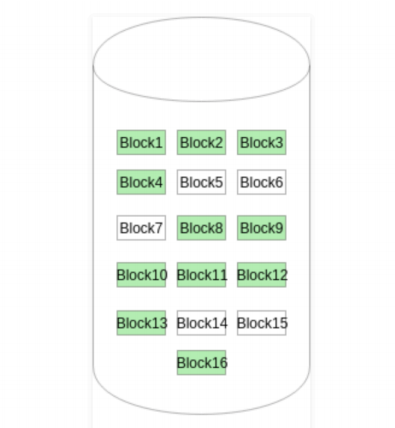
BitMap 位图或者 Bit vector 位向量
位图或位向量是一系列位或位的集合,其中每个位对应一个磁盘块,该位可以采用两个值:0和1,0表示已分配该块,而1表示一个空闲块。下图中的磁盘上给定的磁盘块实例(分配了绿色块)可以用16位的位图表示为:0000111000000110。
使用链表进行管理
在这种方法中,空闲磁盘块链接在一起,即一个空闲块包含指向下一个空闲块的指针。第一个磁盘块的块号存储在磁盘上的单独位置,也缓存在内存中。
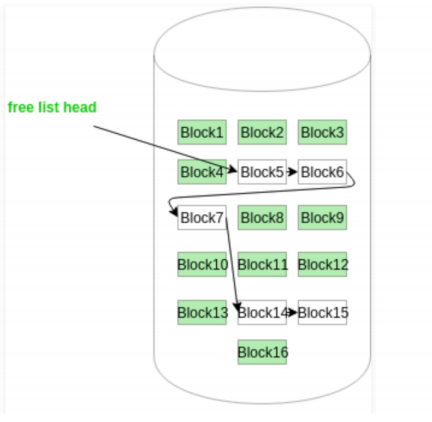
碎片
这里不得不提一个叫做碎片(fragment)的概念,也称为片段。一般零散的单个数据通常称为片段。 磁盘块可以进一步分为固定大小的分配单元,片段只是在驱动器上彼此不相邻的文件片段。
inode
然后在后面是一个 inode(index node),也称作索引节点。它是一个数组的结构,每个文件有一个 inode,inode 非常重要,它说明了文件的方方面面。每个索引节点都存储对象数据的属性和磁盘块位置
有一种简单的方法可以找到它们 ls -lai 命令。让我们看一下根文件系统:

inode 节点主要包括了以下信息
- 模式/权限(保护)
- 所有者 ID
- 组 ID
- 文件大小
- 文件的硬链接数
- 上次访问时间
- 最后修改时间
- inode 上次修改时间
文件分为两部分,索引节点和块。一旦创建后,每种类型的块数是固定的。你不能增加分区上 inode 的数量,也不能增加磁盘块的数量。
紧跟在 inode 后面的是根目录,它存放的是文件系统目录树的根部。最后,磁盘的其他部分存放了其他所有的目录和文件。
文件的实现
最重要的问题是记录各个文件分别用到了哪些磁盘块。不同的系统采用了不同的方法。下面我们会探讨一下这些方式。分配背后的主要思想是有效利用文件空间和快速访问文件 ,主要有三种分配方案
- 连续分配
- 链表分配
- 索引分配
连续分配
最简单的分配方案是把每个文件作为一连串连续数据块存储在磁盘上。因此,在具有 1KB 块的磁盘上,将为 50 KB 文件分配 50 个连续块。
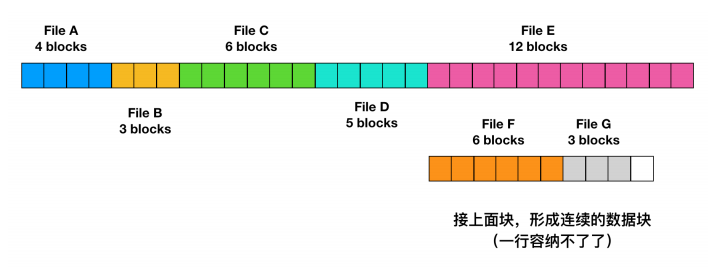
使用连续空间存储文件
上面展示了 40 个连续的内存块。从最左侧的 0 块开始。初始状态下,还没有装载文件,因此磁盘是空的。接着,从磁盘开始处(块 0 )处开始写入占用 4 块长度的内存 A 。然后是一个占用 6 块长度的内存 B,会直接在 A 的末尾开始写。
注意每个文件都会在新的文件块开始写,所以如果文件 A 只占用了 3 又 1/2 个块,那么最后一个块的部分内存会被浪费。在上面这幅图中,总共展示了 7 个文件,每个文件都会从上个文件的末尾块开始写新的文件块。
连续的磁盘空间分配有两个优点。
- 第一,连续文件存储实现起来比较简单,只需要记住两个数字就可以:一个是第一个块的文件地址和文件的块数量。给定第一个块的编号,可以通过简单的加法找到任何其他块的编号。
- 第二点是读取性能比较强,可以通过一次操作从文件中读取整个文件。只需要一次寻找第一个块。后面就不再需要寻道时间和旋转延迟,所以数据会以全带宽进入磁盘。
因此,连续的空间分配具有实现简单、高性能的特点。
不幸的是,连续空间分配也有很明显的不足。随着时间的推移,磁盘会变得很零碎。下图解释了这种现象
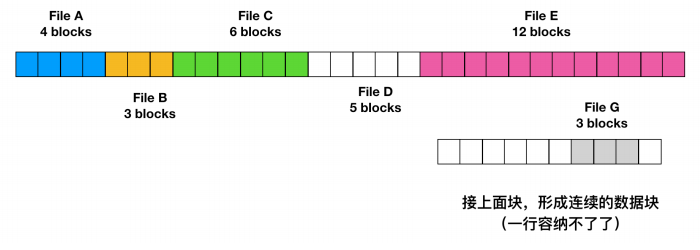
这里有两个文件 D 和 F 被删除了。当删除一个文件时,此文件所占用的块也随之释放,就会在磁盘空间中留下一些空闲块。磁盘并不会在这个位置挤压掉空闲块,因为这会复制空闲块之后的所有文件,可能会有上百万的块,这个量级就太大了。
链表分配
第二种存储文件的方式是为每个文件构造磁盘块链表,每个文件都是磁盘块的链接列表,就像下面所示
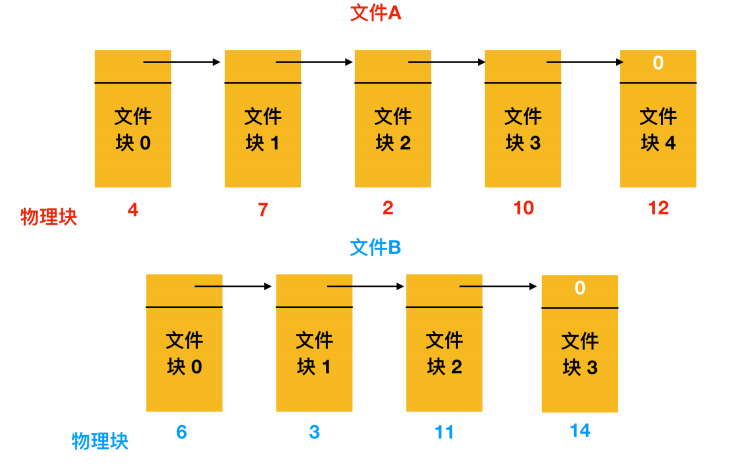
以磁盘块的链表形式存储文件
每个块的第一个字作为指向下一块的指针,块的其他部分存放数据。如果上面这张图你看的不是很清楚的话,可以看看整个的链表分配方案
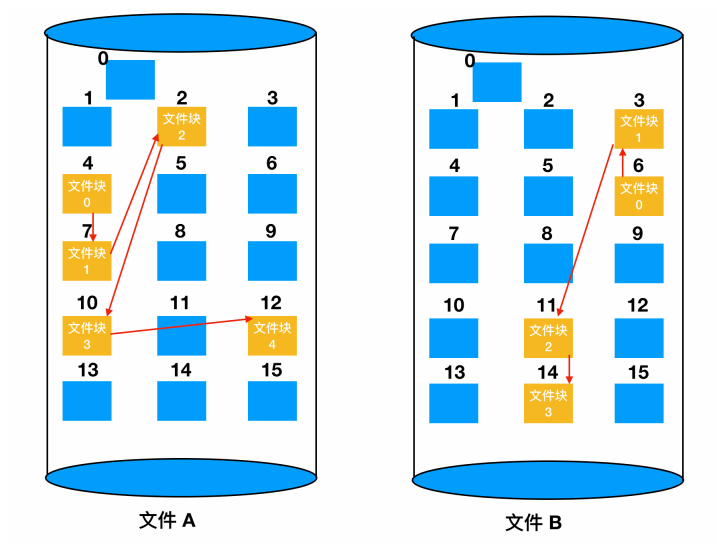
与连续分配方案不同,这一方法可以充分利用每个磁盘块。除了最后一个磁盘块外,不会因为磁盘碎片而浪费存储空间。同样,在目录项中,只要存储了第一个文件块,那么其他文件块也能够被找到。
另一方面,在链表的分配方案中,尽管顺序读取非常方便,但是随机访问却很困难(这也是数组和链表数据结构的一大区别)。
还有一个问题是,由于指针会占用一些字节,每个磁盘块实际存储数据的字节数并不再是 2 的整数次幂。虽然这个问题并不会很严重,但是这种方式降低了程序运行效率。许多程序都是以长度为 2 的整数次幂来读写磁盘,由于每个块的前几个字节被指针所使用,所以要读出一个完成的块大小信息,就需要当前块的信息和下一块的信息拼凑而成,因此就引发了查找和拼接的开销。
使用内存表进行链表分配
由于连续分配和链表分配都有其不可忽视的缺点。所以提出了使用内存中的表来解决分配问题。取出每个磁盘块的指针字,把它们放在内存的一个表中,就可以解决上述链表的两个不足之处。下面是一个例子

上图表示了链表形成的磁盘块的内容。这两个图中都有两个文件,文件 A 依次使用了磁盘块地址 4、7、 2、 10、 12,文件 B 使用了6、3、11 和 14。也就是说,文件 A 从地址 4 处开始,顺着链表走就能找到文件 A 的全部磁盘块。同样,从第 6 块开始,顺着链走到最后,也能够找到文件 B 的全部磁盘块。你会发现,这两个链表都以不属于有效磁盘编号的特殊标记(-1)结束。内存中的这种表格称为 文件分配表(File Application Table,FAT)。
目录的实现
文件只有打开后才能够被读取。在文件打开后,操作系统会使用用户提供的路径名来定位磁盘中的目录。目录项提供了查找文件磁盘块所需要的信息。根据系统的不同,提供的信息也不同,可能提供的信息是整个文件的磁盘地址,或者是第一个块的数量(两个链表方案)或 inode的数量。不过不管用那种情况,目录系统的主要功能就是 将文件的 ASCII 码的名称映射到定位数据所需的信息上。
共享文件
当多个用户在同一个项目中工作时,他们通常需要共享文件。如果这个共享文件同时出现在多个用户目录下,那么他们协同工作起来就很方便。下面的这张图我们在上面提到过,但是有一个更改的地方,就是 C 的一个文件也出现在了 B 的目录下。
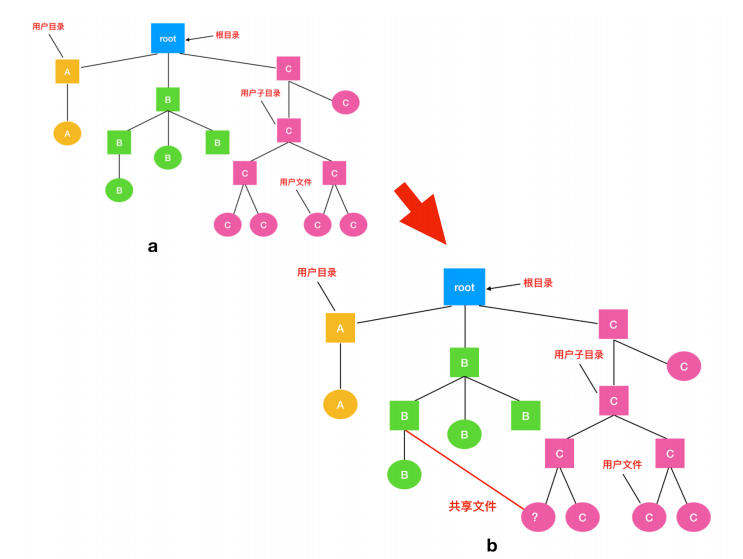
如果按照如上图的这种组织方式而言,那么 B 的目录与该共享文件的联系称为 链接(link)。那么文件系统现在就是一个 有向无环图(Directed Acyclic Graph, 简称 DAG),而不是一棵树了。
日志结构文件系统
技术的改变会给当前的文件系统带来压力。这种情况下,CPU 会变得越来越快,磁盘会变得越来越大并且越来越便宜(但不会越来越快)。内存容量也是以指数级增长。但是磁盘的寻道时间(除了固态盘,因为固态盘没有寻道时间)并没有获得提高。
为此,Berkeley 设计了一种全新的文件系统,试图缓解这个问题,这个文件系统就是 日志结构文件系统(Log-structured File System, LFS)。旨在解决以下问题。
- 不断增长的系统内存
- 顺序 I/O 性能胜过随机 I/O 性能
- 现有低效率的文件系统
- 文件系统不支持 RAID(虚拟化)
另一方面,当时的文件系统不论是 UNIX 还是 FFS,都有大量的随机读写(在 FFS 中创建一个新文件至少需要5次随机写),因此成为整个系统的性能瓶颈。同时因为 Page cache 的存在,作者认为随机读不是主要问题:随着越来越大的内存,大部分的读操作都能被 cache,因此 LFS 主要要解决的是减少对硬盘的随机写操作。
在这种设计中,inode 甚至具有与 UNIX 中相同的结构,但是现在它们分散在整个日志中,而不是位于磁盘上的固定位置。所以,inode 很定位。为了能够找到 inode ,维护了一个由 inode 索引的 inode map(inode 映射)。表项 i 指向磁盘中的第 i 个 inode 。这个映射保存在磁盘中,但是也保存在缓存中,因此,使用最频繁的部分大部分时间都在内存中。

到目前为止,所有写入最初都缓存在内存中,并且追加在日志末尾,所有缓存的写入都定期在单个段中写入磁盘。所以,现在打开文件也就意味着用映射定位文件的索引节点。一旦 inode 被定位后,磁盘块的地址就能够被找到。所有这些块本身都将位于日志中某处的分段中。
真实情况下的磁盘容量是有限的,所以最终日志会占满整个磁盘空间,这种情况下就会出现没有新的磁盘块被写入到日志中。幸运的是,许多现有段可能具有不再需要的块。例如,如果一个文件被覆盖了,那么它的 inode 将被指向新的块,但是旧的磁盘块仍在先前写入的段中占据着空间。
为了处理这个问题,LFS 有一个清理(clean)线程,它会循环扫描日志并对日志进行压缩。首先,通过查看日志中第一部分的信息来查看其中存在哪些索引节点和文件。它会检查当前 inode 的映射来查看 inode 否在在当前块中,是否仍在被使用。如果不是,该信息将被丢弃。如果仍然在使用,那么 inode 和块就会进入内存等待写回到下一个段中。然后原来的段被标记为空闲,以便日志可以用来存放新的数据。用这种方法,清理线程遍历日志,从后面移走旧的段,然后将有效的数据放入内存等待写到下一个段中。由此一来整个磁盘会形成一个大的环形缓冲区,写线程将新的段写在前面,而清理线程则清理后面的段。
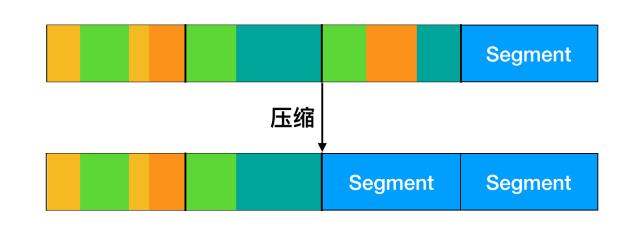
日志文件系统
虽然日志结构系统的设计很优雅,但是由于它们和现有的文件系统不相匹配,因此还没有广泛使用。不过,从日志文件结构系统衍生出来一种新的日志系统,叫做日志文件系统,它会记录系统下一步将要做什么的日志。微软的 NTFS 文件系统、Linux 的 ext3 就使用了此日志。 OS X 将日志系统作为可供选项。为了看清它是如何工作的,我们下面讨论一个例子,比如 移除文件 ,这个操作在 UNIX 中需要三个步骤完成:
- 在目录中删除文件
- 释放 inode 到空闲 inode 池
- 将所有磁盘块归还给空闲磁盘池。
虚拟文件系统
UNIX 操作系统使用一种 虚拟文件系统(Virtual File System, VFS) 来尝试将多种文件系统构成一个有序的结构。关键的思想是抽象出所有文件系统都共有的部分,并将这部分代码放在一层,这一层再调用具体文件系统来管理数据。下面是一个 VFS 的系统结构
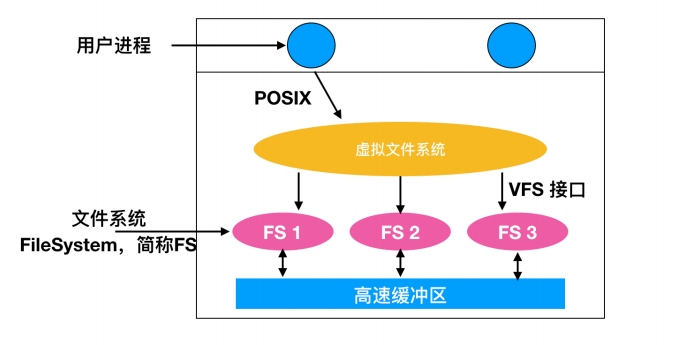
还是那句经典的话,在计算机世界中,任何解决不了的问题都可以加个代理来解决。所有和文件相关的系统调用在最初的处理上都指向虚拟文件系统。这些来自用户进程的调用,都是标准的 POSIX 系统调用,比如 open、read、write 和 seek 等。VFS 对用户进程有一个 上层 接口,这个接口就是著名的 POSIX 接口。
文件系统的管理和优化
能够使文件系统工作是一回事,能够使文件系统高效、稳定的工作是另一回事,下面我们就来探讨一下文件系统的管理和优化。
磁盘空间管理
文件通常存在磁盘中,所以如何管理磁盘空间是一个操作系统的设计者需要考虑的问题。在文件上进行存有两种策略:分配 n 个字节的连续磁盘空间;或者把文件拆分成多个并不一定连续的块。在存储管理系统中,主要有分段管理和 分页管理 两种方式。
正如我们所看到的,按连续字节序列存储文件有一个明显的问题,当文件扩大时,有可能需要在磁盘上移动文件。内存中分段也有同样的问题。不同的是,相对于把文件从磁盘的一个位置移动到另一个位置,内存中段的移动操作要快很多。因此,几乎所有的文件系统都把文件分割成固定大小的块来存储。
块大小
一旦把文件分为固定大小的块来存储,就会出现问题,块的大小是多少?按照磁盘组织方式,扇区、磁道和柱面显然都可以作为分配单位。在分页系统中,分页大小也是主要因素。
拥有大的块尺寸意味着每个文件,甚至 1 字节文件,都要占用一个柱面空间,也就是说小文件浪费了大量的磁盘空间。另一方面,小块意味着大部分文件将会跨越多个块,因此需要多次搜索和旋转延迟才能读取它们,从而降低了性能。因此,如果分配的块太大会浪费空间;分配的块太小会浪费时间。
记录空闲块
一旦指定了块大小,下一个问题就是怎样跟踪空闲块。有两种方法被广泛采用,如下图所示
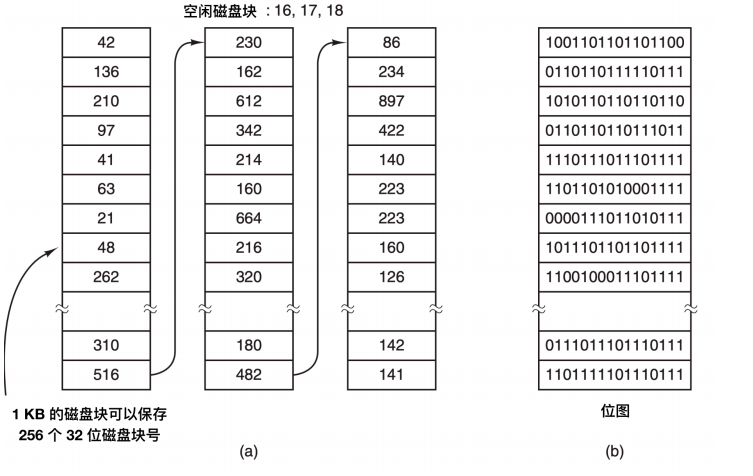
第一种方法是采用磁盘块链表,链表的每个块中包含极可能多的空闲磁盘块号。对于 1 KB 的块和 32 位的磁盘块号,空闲表中每个块包含有 255 个空闲的块号。考虑 1 TB 的硬盘,拥有大概十亿个磁盘块。为了存储全部地址块号,如果每块可以保存 255 个块号,则需要将近 400 万个块。通常,空闲块用于保存空闲列表,因此存储基本上是空闲的。
另一种空闲空间管理的技术是位图(bitmap),n 个块的磁盘需要 n 位位图。在位图中,空闲块用 1 表示,已分配的块用 0 表示。对于 1 TB 硬盘的例子,需要 10 亿位表示,即需要大约 130 000 个 1 KB 块存储。很明显,和 32 位链表模型相比,位图需要的空间更少,因为每个块使用 1 位。只有当磁盘快满的时候,链表需要的块才会比位图少。
磁盘配额
为了防止一些用户占用太多的磁盘空间,多用户操作通常提供一种磁盘配额(enforcing disk quotas)的机制。系统管理员为每个用户分配最大的文件和块分配,并且操作系统确保用户不会超过其配额。我们下面会谈到这一机制。
在用户打开一个文件时,操作系统会找到文件属性和磁盘地址,并把它们送入内存中的打开文件表。其中一个属性告诉文件所有者是谁。任何有关文件的增加都会记到所有者的配额中。
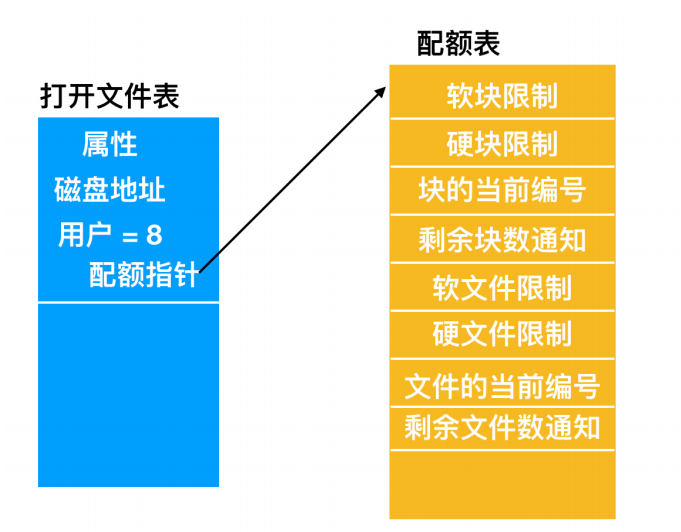
配额表中记录了每个用户的配额
第二张表包含了每个用户当前打开文件的配额记录,即使是其他人打开该文件也一样。如上图所示,该表的内容是从被打开文件的所有者的磁盘配额文件中提取出来的。当所有文件关闭时,该记录被写回配额文件。
当在打开文件表中建立一新表项时,会产生一个指向所有者配额记录的指针。每次向文件中添加一个块时,文件所有者所用数据块的总数也随之增加,并会同时增加硬限制和软限制的检查。可以超出软限制,但硬限制不可以超出。当已达到硬限制时,再往文件中添加内容将引发错误。同样,对文件数目也存在类似的检查。
文件系统备份
做文件备份很耗费时间而且也很浪费空间,这会引起下面几个问题。首先,是要备份整个文件还是仅备份一部分呢?一般来说,只是备份特定目录及其下的全部文件,而不是备份整个文件系统。
其次,对上次未修改过的文件再进行备份是一种浪费,因而产生了一种增量转储(incremental dumps) 的思想。最简单的增量转储的形式就是周期性的做全面的备份,而每天只对增量转储完成后发生变化的文件做单个备份。
稍微好一点的方式是只备份最近一次转储以来更改过的文件。当然,这种做法极大的缩减了转储时间,但恢复起来却更复杂,因为最近的全面转储先要全部恢复,随后按逆序进行增量转储。为了方便恢复,人们往往使用更复杂的转储模式。
第三,既然待转储的往往是海量数据,那么在将其写入磁带之前对文件进行压缩就很有必要。但是,如果在备份过程中出现了文件损坏的情况,就会导致破坏压缩算法,从而使整个磁带无法读取。所以在备份前是否进行文件压缩需慎重考虑。
第四,对正在使用的文件系统做备份是很难的。如果在转储过程中要添加,删除和修改文件和目录,则转储结果可能不一致。因此,因为转储过程中需要花费数个小时的时间,所以有必要在晚上将系统脱机进行备份,然而这种方式的接受程度并不高。所以,人们修改了转储算法,记下文件系统的瞬时快照,即复制关键的数据结构,然后需要把将来对文件和目录所做的修改复制到块中,而不是到处更新他们。
磁盘转储到备份磁盘上有两种方案:物理转储和逻辑转储。物理转储(physical dump) 是从磁盘的 0 块开始,依次将所有磁盘块按照顺序写入到输出磁盘,并在复制最后一个磁盘时停止。这种程序的万无一失性是其他程序所不具备的。
第二个需要考虑的是坏块的转储。制造大型磁盘而没有瑕疵是不可能的,所以也会存在一些坏块(bad blocks)。有时进行低级格式化后,坏块会被检测出来并进行标记,这种情况的解决办法是用磁盘末尾的一些空闲块所替换。
然而,一些块在格式化后会变坏,在这种情况下操作系统可以检测到它们。通常情况下,它可以通过创建一个由所有坏块组成的文件来解决问题,确保它们不会出现在空闲池中并且永远不会被分配。那么此文件是完全不可读的。如果磁盘控制器将所有的坏块重新映射,物理转储还是能够正常工作的。
Windows 系统有分页文件(paging files) 和 休眠文件(hibernation files) 。它们在文件还原时不发挥作用,同时也不应该在第一时间进行备份。
文件系统的一致性
影响可靠性的一个因素是文件系统的一致性。许多文件系统读取磁盘块、修改磁盘块、再把它们写回磁盘。如果系统在所有块写入之前崩溃,文件系统就会处于一种不一致(inconsistent)的状态。如果某些尚未写回的块是索引节点块,目录块或包含空闲列表的块,则此问题是很严重的。
为了处理文件系统一致性问题,大部分计算机都会有应用程序来检查文件系统的一致性。例如,UNIX 有 fsck;Windows 有 sfc,每当引导系统时(尤其是在崩溃后),都可以运行该程序。
可以进行两种一致性检查:块的一致性检查和文件的一致性检查。为了检查块的一致性,应用程序会建立两张表,每个包含一个计数器的块,最初设置为 0 。第一个表中的计数器跟踪该块在文件中出现的次数,第二张表中的计数器记录每个块在空闲列表、空闲位图中出现的频率。
文件系统性能
访问磁盘的效率要比内存满的多,是时候又祭出这张图了
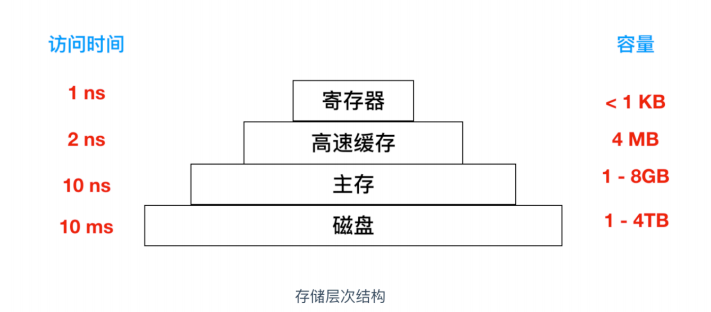
从内存读一个 32 位字大概是 10ns,从硬盘上读的速率大概是 100MB/S,对每个 32 位字来说,效率会慢了四倍,另外,还要加上 5 - 10 ms 的寻道时间等其他损耗,如果只访问一个字,内存要比磁盘快百万数量级。所以磁盘优化是很有必要的,下面我们会讨论几种优化方式
高速缓存
最常用的减少磁盘访问次数的技术是使用 块高速缓存(block cache) 或者 缓冲区高速缓存(buffer cache)。高速缓存指的是一系列的块,它们在逻辑上属于磁盘,但实际上基于性能的考虑被保存在内存中。
管理高速缓存有不同的算法,常用的算法是:检查全部的读请求,查看在高速缓存中是否有所需要的块。如果存在,可执行读操作而无须访问磁盘。如果检查块不再高速缓存中,那么首先把它读入高速缓存,再复制到所需的地方。之后,对同一个块的请求都通过高速缓存来完成。
高速缓存的操作如下图所示
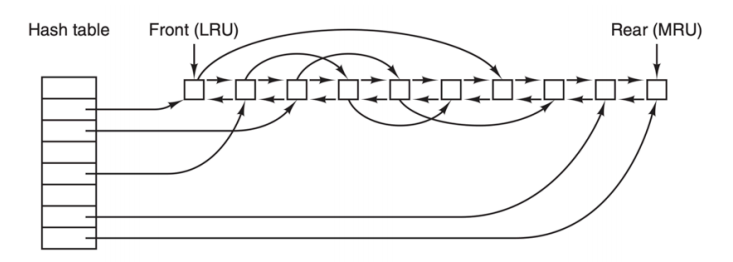
由于在高速缓存中有许多块,所以需要某种方法快速确定所需的块是否存在。常用方法是将设备和磁盘地址进行散列操作,然后,在散列表中查找结果。具有相同散列值的块在一个链表中连接在一起(这个数据结构是不是很像 HashMap?),这样就可以沿着冲突链查找其他块。
如果高速缓存已满,此时需要调入新的块,则要把原来的某一块调出高速缓存,如果要调出的块在上次调入后已经被修改过,则需要把它写回磁盘。
块提前读
第二个明显提高文件系统的性能是,在需要用到块之前,试图提前将其写入高速缓存,从而提高命中率。许多文件都是顺序读取。如果请求文件系统在某个文件中生成块 k,文件系统执行相关操作并且在完成之后,会检查高速缓存,以便确定块 k + 1 是否已经在高速缓存。如果不在,文件系统会为 k + 1 安排一个预读取,因为文件希望在用到该块的时候能够直接从高速缓存中读取。
当然,块提前读取策略只适用于实际顺序读取的文件。对随机访问的文件,提前读丝毫不起作用。甚至还会造成阻碍。
减少磁盘臂运动
高速缓存和块提前读并不是提高文件系统性能的唯一方法。另一种重要的技术是把有可能顺序访问的块放在一起,当然最好是在同一个柱面上,从而减少磁盘臂的移动次数。当写一个输出文件时,文件系统就必须按照要求一次一次地分配磁盘块。如果用位图来记录空闲块,并且整个位图在内存中,那么选择与前一块最近的空闲块是很容易的。如果用空闲表,并且链表的一部分存在磁盘上,要分配紧邻的空闲块就会困难很多。
磁盘碎片整理
在初始安装操作系统后,文件就会被不断的创建和清除,于是磁盘会产生很多的碎片,在创建一个文件时,它使用的块会散布在整个磁盘上,降低性能。删除文件后,回收磁盘块,可能会造成空穴。
磁盘性能可以通过如下方式恢复:移动文件使它们相互挨着,并把所有的至少是大部分的空闲空间放在一个或多个大的连续区域内。Windows 有一个程序 defrag 就是做这个事儿的。Windows 用户会经常使用它,SSD 除外。
磁盘碎片整理程序会在让文件系统上很好地运行。Linux 文件系统(特别是 ext2 和 ext3)由于其选择磁盘块的方式,在磁盘碎片整理上一般不会像 Windows 一样困难,因此很少需要手动的磁盘碎片整理。而且,固态硬盘并不受磁盘碎片的影响,事实上,在固态硬盘上做磁盘碎片整理反倒是多此一举,不仅没有提高性能,反而磨损了固态硬盘。所以碎片整理只会缩短固态硬盘的寿命。
下面我们来探讨一下 I/O 流程问题。
I/O 设备
什么是 I/O 设备?I/O 设备又叫做输入/输出设备,它是人类用来和计算机进行通信的外部硬件。输入/输出设备能够向计算机发送数据(输出)并从计算机接收数据(输入)。
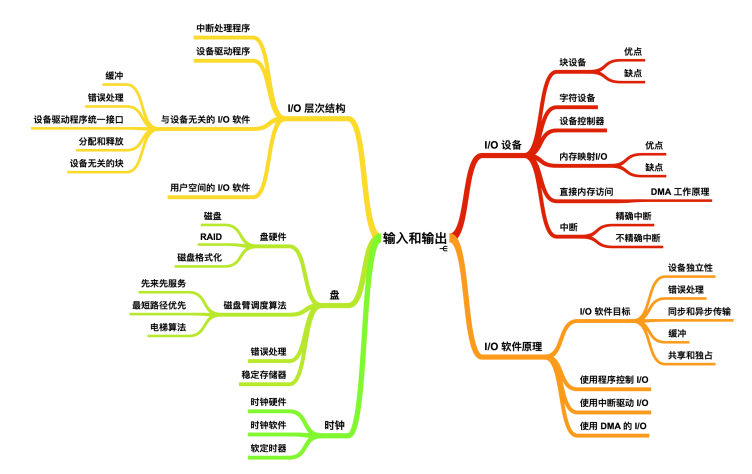
I/O 设备(I/O devices)可以分成两种:块设备(block devices) 和 字符设备(character devices)。
块设备
块设备是一个能存储固定大小块信息的设备,它支持以固定大小的块,扇区或群集读取和(可选)写入数据。每个块都有自己的物理地址。通常块的大小在 512 - 65536 之间。所有传输的信息都会以连续的块为单位。块设备的基本特征是每个块都较为对立,能够独立的进行读写。常见的块设备有 硬盘、蓝光光盘、USB 盘
与字符设备相比,块设备通常需要较少的引脚。

块设备的缺点
基于给定固态存储器的块设备比基于相同类型的存储器的字节寻址要慢一些,因为必须在块的开头开始读取或写入。所以,要读取该块的任何部分,必须寻找到该块的开始,读取整个块,如果不使用该块,则将其丢弃。要写入块的一部分,必须寻找到块的开始,将整个块读入内存,修改数据,再次寻找到块的开头处,然后将整个块写回设备。
字符设备
另一类 I/O 设备是字符设备。字符设备以字符为单位发送或接收一个字符流,而不考虑任何块结构。字符设备是不可寻址的,也没有任何寻道操作。常见的字符设备有 打印机、网络设备、鼠标、以及大多数与磁盘不同的设备。

设备控制器
设备控制器是处理 CPU 传入和传出信号的系统。设备通过插头和插座连接到计算机,并且插座连接到设备控制器。设备控制器从连接的设备处接收数据,并将其存储在控制器内部的一些特殊目的寄存器(special purpose registers) 也就是本地缓冲区中。
每个设备控制器都会有一个应用程序与之对应,设备控制器通过应用程序的接口通过中断与操作系统进行通信。设备控制器是硬件,而设备驱动程序是软件。
内存映射 I/O
每个控制器都会有几个寄存器用来和 CPU 进行通信。通过写入这些寄存器,操作系统可以命令设备发送数据,接收数据、开启或者关闭设备等。通过从这些寄存器中读取信息,操作系统能够知道设备的状态,是否准备接受一个新命令等。
为了控制寄存器,许多设备都会有数据缓冲区(data buffer),来供系统进行读写。
那么问题来了,CPU 如何与设备寄存器和设备数据缓冲区进行通信呢?存在两个可选的方式。第一种方法是,每个控制寄存器都被分配一个 I/O 端口(I/O port)号,这是一个 8 位或 16 位的整数。所有 I/O 端口的集合形成了受保护的 I/O 端口空间,以便普通用户程序无法访问它(只有操作系统可以访问)。使用特殊的 I/O 指令像是
IN REG,PORT
CPU 可以读取控制寄存器 PORT 的内容并将结果放在 CPU 寄存器 REG 中。类似的,使用
OUT PORT,REG
CPU 可以将 REG 的内容写到控制寄存器中。大多数早期计算机,包括几乎所有大型主机,如 IBM 360 及其所有后续机型,都是以这种方式工作的。
第二个方法是 PDP-11 引入的,它将所有控制寄存器映射到内存空间中。
直接内存访问
无论一个 CPU 是否具有内存映射 I/O,它都需要寻址设备控制器以便与它们交换数据。CPU 可以从 I/O 控制器每次请求一个字节的数据,但是这么做会浪费 CPU 时间,所以经常会用到一种称为直接内存访问(Direct Memory Access) 的方案。为了简化,我们假设 CPU 通过单一的系统总线访问所有的设备和内存,该总线连接 CPU 、内存和 I/O 设备,如下图所示
DMA 传送操作
现代操作系统实际更为复杂,但是原理是相同的。如果硬件有 DMA 控制器,那么操作系统只能使用 DMA。有时这个控制器会集成到磁盘控制器和其他控制器中,但这种设计需要在每个设备上都装有一个分离的 DMA 控制器。单个的 DMA 控制器可用于向多个设备传输,这种传输往往同时进行。
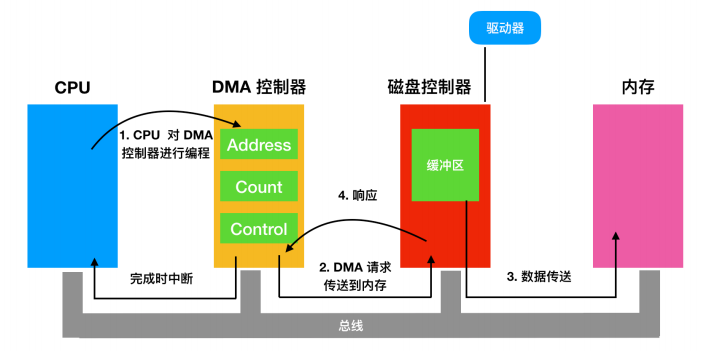
DMA 工作原理
首先 CPU 通过设置 DMA 控制器的寄存器对它进行编程,所以 DMA 控制器知道将什么数据传送到什么地方。DMA 控制器还要向磁盘控制器发出一个命令,通知它从磁盘读数据到其内部的缓冲区并检验校验和。当有效数据位于磁盘控制器的缓冲区中时,DMA 就可以开始了。
DMA 控制器通过在总线上发出一个读请求到磁盘控制器而发起 DMA 传送,这是第二步。这个读请求就像其他读请求一样,磁盘控制器并不知道或者并不关心它是来自 CPU 还是来自 DMA 控制器。通常情况下,要写的内存地址在总线的地址线上,所以当磁盘控制器去匹配下一个字时,它知道将该字写到什么地方。写到内存就是另外一个总线循环了,这是第三步。当写操作完成时,磁盘控制器在总线上发出一个应答信号到 DMA 控制器,这是第四步。
然后,DMA 控制器会增加内存地址并减少字节数量。如果字节数量仍然大于 0 ,就会循环步骤 2 - 步骤 4 ,直到字节计数变为 0 。此时,DMA 控制器会打断 CPU 并告诉它传输已经完成了。
重温中断
在一台个人计算机体系结构中,中断结构会如下所示
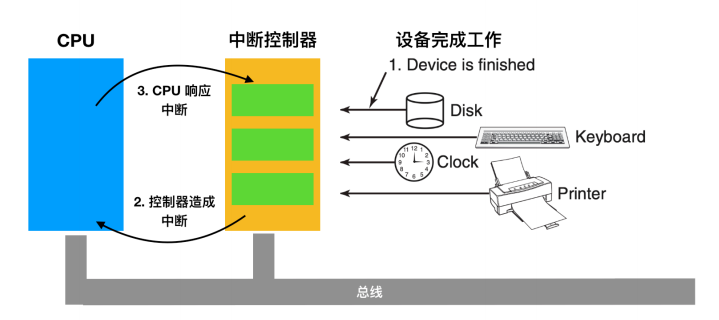
中断是怎样发生的
当一个 I/O 设备完成它的工作后,它就会产生一个中断(默认操作系统已经开启中断),它通过在总线上声明已分配的信号来实现此目的。主板上的中断控制器芯片会检测到这个信号,然后执行中断操作。
精确中断和不精确中断
使机器处于良好状态的中断称为精确中断(precise interrupt)。这样的中断具有四个属性:
- PC (程序计数器)保存在一个已知的地方
- PC 所指向的指令之前所有的指令已经完全执行
- PC 所指向的指令之后所有的指令都没有执行
- PC 所指向的指令的执行状态是已知的
不满足以上要求的中断称为 不精确中断(imprecise interrupt),不精确中断让人很头疼。上图描述了不精确中断的现象。指令的执行时序和完成度具有不确定性,而且恢复起来也非常麻烦。
IO 软件原理
I/O 软件目标
设备独立性
I/O 软件设计一个很重要的目标就是设备独立性(device independence)。这意味着我们能够编写访问任何设备的应用程序,而不用事先指定特定的设备。
错误处理
除了设备独立性外,I/O 软件实现的第二个重要的目标就是错误处理(error handling)。通常情况下来说,错误应该交给硬件层面去处理。如果设备控制器发现了读错误的话,它会尽可能的去修复这个错误。如果设备控制器处理不了这个问题,那么设备驱动程序应该进行处理,设备驱动程序会再次尝试读取操作,很多错误都是偶然性的,如果设备驱动程序无法处理这个错误,才会把错误向上抛到硬件层面(上层)进行处理,很多时候,上层并不需要知道下层是如何解决错误的。
同步和异步传输
I/O 软件实现的第三个目标就是 同步(synchronous) 和 异步(asynchronous,即中断驱动)传输。这里先说一下同步和异步是怎么回事吧。
同步传输中数据通常以块或帧的形式发送。发送方和接收方在数据传输之前应该具有同步时钟。而在异步传输中,数据通常以字节或者字符的形式发送,异步传输则不需要同步时钟,但是会在传输之前向数据添加奇偶校验位。大部分物理IO(physical I/O) 是异步的。物理 I/O 中的 CPU 是很聪明的,CPU 传输完成后会转而做其他事情,它和中断心灵相通,等到中断发生后,CPU 才会回到传输这件事情上来。
缓冲
I/O 软件的最后一个问题是缓冲(buffering)。通常情况下,从一个设备发出的数据不会直接到达最后的设备。其间会经过一系列的校验、检查、缓冲等操作才能到达。
共享和独占
I/O 软件引起的最后一个问题就是共享设备和独占设备的问题。有些 I/O 设备能够被许多用户共同使用。一些设备比如磁盘,让多个用户使用一般不会产生什么问题,但是某些设备必须具有独占性,即只允许单个用户使用完成后才能让其他用户使用。
一共有三种控制 I/O 设备的方法
- 使用程序控制 I/O
- 使用中断驱动 I/O
- 使用 DMA 驱动 I/O
I/O 层次结构
I/O 软件通常组织成四个层次,它们的大致结构如下图所示

下面我们具体的来探讨一下上面的层次结构
中断处理程序
在计算机系统中,中断就像女人的脾气一样无时无刻都在产生,中断的出现往往是让人很不爽的。中断处理程序又被称为中断服务程序 或者是 ISR(Interrupt Service Routines),它是最靠近硬件的一层。中断处理程序由硬件中断、软件中断或者是软件异常启动产生的中断,用于实现设备驱动程序或受保护的操作模式(例如系统调用)之间的转换。
中断处理程序负责处理中断发生时的所有操作,操作完成后阻塞,然后启动中断驱动程序来解决阻塞。通常会有三种通知方式,依赖于不同的具体实现
- 信号量实现中:在信号量上使用
up进行通知; - 管程实现:对管程中的条件变量执行
signal操作
- 还有一些情况是发送一些消息
设备驱动程序
每个连接到计算机的 I/O 设备都需要有某些特定设备的代码对其进行控制。这些提供 I/O 设备到设备控制器转换的过程的代码称为 设备驱动程序(Device driver)。
设备控制器的主要功能有下面这些
- 接收和识别命令:设备控制器可以接受来自 CPU 的指令,并进行识别。设备控制器内部也会有寄存器,用来存放指令和参数
- 进行数据交换:CPU、控制器和设备之间会进行数据的交换,CPU 通过总线把指令发送给控制器,或从控制器中并行地读出数据;控制器将数据写入指定设备。
- 地址识别:每个硬件设备都有自己的地址,设备控制器能够识别这些不同的地址,来达到控制硬件的目的,此外,为使 CPU 能向寄存器中写入或者读取数据,这些寄存器都应具有唯一的地址。
- 差错检测:设备控制器还具有对设备传递过来的数据进行检测的功能。
在这种情况下,设备控制器会阻塞,直到中断来解除阻塞状态。还有一种情况是操作是可以无延迟的完成,所以驱动程序不需要阻塞。在第一种情况下,操作系统可能被中断唤醒;第二种情况下操作系统不会被休眠。
设备驱动程序必须是可重入的,因为设备驱动程序会阻塞和唤醒然后再次阻塞。驱动程序不允许进行系统调用,但是它们通常需要与内核的其余部分进行交互。
与设备无关的 I/O 软件
I/O 软件有两种,一种是我们上面介绍过的基于特定设备的,还有一种是设备无关性的,设备无关性也就是不需要特定的设备。设备驱动程序与设备无关的软件之间的界限取决于具体的系统。下面显示的功能由设备无关的软件实现

与设备无关的软件的基本功能是对所有设备执行公共的 I/O 功能,并且向用户层软件提供一个统一的接口。
缓冲
无论是对于块设备还是字符设备来说,缓冲都是一个非常重要的考量标准。缓冲技术应用广泛,但它也有缺点。如果数据被缓冲次数太多,会影响性能。
错误处理
在 I/O 中,出错是一种再正常不过的情况了。当出错发生时,操作系统必须尽可能处理这些错误。有一些错误是只有特定的设备才能处理,有一些是由框架进行处理,这些错误和特定的设备无关。
I/O 错误的一类是程序员编程错误,比如还没有打开文件前就读流,或者不关闭流导致内存溢出等等。这类问题由程序员处理;另外一类是实际的 I/O 错误,例如向一个磁盘坏块写入数据,无论怎么写都写入不了。这类问题由驱动程序处理,驱动程序处理不了交给硬件处理,这个我们上面也说过。
设备驱动程序统一接口
我们在操作系统概述中说到,操作系统一个非常重要的功能就是屏蔽了硬件和软件的差异性,为硬件和软件提供了统一的标准,这个标准还体现在为设备驱动程序提供统一的接口,因为不同的硬件和厂商编写的设备驱动程序不同,所以如果为每个驱动程序都单独提供接口的话,这样没法搞,所以必须统一。
分配和释放
一些设备例如打印机,它只能由一个进程来使用,这就需要操作系统根据实际情况判断是否能够对设备的请求进行检查,判断是否能够接受其他请求,一种比较简单直接的方式是在特殊文件上执行 open操作。如果设备不可用,那么直接 open 会导致失败。还有一种方式是不直接导致失败,而是让其阻塞,等到另外一个进程释放资源后,在进行 open 打开操作。这种方式就把选择权交给了用户,由用户判断是否应该等待。
设备无关的块
不同的磁盘会具有不同的扇区大小,但是软件不会关心扇区大小,只管存储就是了。一些字符设备可以一次一个字节的交付数据,而其他的设备则以较大的单位交付数据,这些差异也可以隐藏起来。
用户空间的 I/O 软件
虽然大部分 I/O 软件都在内核结构中,但是还有一些在用户空间实现的 I/O 软件,凡事没有绝对。一些 I/O 软件和库过程在用户空间存在,然后以提供系统调用的方式实现。
盘
盘可以说是硬件里面比较简单的构造了,同时也是最重要的。下面我们从盘谈起,聊聊它的物理构造
盘硬件
盘会有很多种类型。其中最简单的构造就是磁盘(magnetic hard disks), 也被称为 hard disk,HDD等。磁盘通常与安装在磁臂上的磁头配对,磁头可将数据读取或者将数据写入磁盘,因此磁盘的读写速度都同样快。在磁盘中,数据是随机访问的,这也就说明可以通过任意的顺序来存储和检索单个数据块,所以你可以在任意位置放置磁盘来让磁头读取,磁盘是一种非易失性的设备,即使断电也能永久保留。
磁盘
为了组织和检索数据,会将磁盘组织成特定的结构,这些特定的结构就是磁道、扇区和柱面

磁盘被组织成柱面形式,每个盘用轴相连,每一个柱面包含若干磁道,每个磁道由若干扇区组成。软盘上大约每个磁道有 8 - 32 个扇区,硬盘上每条磁道上扇区的数量可达几百个,磁头大约是 1 - 16 个。
对于磁盘驱动程序来说,一个非常重要的特性就是控制器是否能够同时控制两个或者多个驱动器进行磁道寻址,这就是重叠寻道(overlapped seek)。对于控制器来说,它能够控制一个磁盘驱动程序完成寻道操作,同时让其他驱动程序等待寻道结束。控制器也可以在一个驱动程序上进行读写草哦做,与此同时让另外的驱动器进行寻道操作,但是软盘控制器不能在两个驱动器上进行读写操作。
RAID
RAID 称为 磁盘冗余阵列,简称 磁盘阵列。利用虚拟化技术把多个硬盘结合在一起,成为一个或多个磁盘阵列组,目的是提升性能或数据冗余。
RAID 有不同的级别
- RAID 0 - 无容错的条带化磁盘阵列
- RAID 1 - 镜像和双工
- RAID 2 - 内存式纠错码
- RAID 3 - 比特交错奇偶校验
- RAID 4 - 块交错奇偶校验
- RAID 5 - 块交错分布式奇偶校验
- RAID 6 - P + Q冗余
磁盘格式化
磁盘由一堆铝的、合金或玻璃的盘片组成,磁盘刚被创建出来后,没有任何信息。磁盘在使用前必须经过低级格式化(low-levvel format),下面是一个扇区的格式

前导码相当于是标示扇区的开始位置,通常以位模式开始,前导码还包括柱面号、扇区号等一些其他信息。紧随前导码后面的是数据区,数据部分的大小由低级格式化程序来确定。大部分磁盘使用 512 字节的扇区。数据区后面是 ECC,ECC 的全称是 error correction code ,数据纠错码,它与普通的错误检测不同,ECC 还可以用于恢复读错误。ECC 阶段的大小由不同的磁盘制造商实现。ECC 大小的设计标准取决于设计者愿意牺牲多少磁盘空间来提高可靠性,以及程序可以处理的 ECC 的复杂程度。通常情况下 ECC 是 16 位,除此之外,硬盘一般具有一定数量的备用扇区,用于替换制造缺陷的扇区。
磁盘臂调度算法
下面我们来探讨一下关于影响磁盘读写的算法,一般情况下,影响磁盘快读写的时间由下面几个因素决定
- 寻道时间 - 寻道时间指的就是将磁盘臂移动到需要读取磁盘块上的时间
- 旋转延迟 - 等待合适的扇区旋转到磁头下所需的时间
- 实际数据的读取或者写入时间
这三种时间参数也是磁盘寻道的过程。一般情况下,寻道时间对总时间的影响最大,所以,有效的降低寻道时间能够提高磁盘的读取速度。
如果磁盘驱动程序每次接收一个请求并按照接收顺序完成请求,这种处理方式也就是 先来先服务(First-Come, First-served, FCFS) ,这种方式很难优化寻道时间。因为每次都会按照顺序处理,不管顺序如何,有可能这次读完后需要等待一个磁盘旋转一周才能继续读取,而其他柱面能够马上进行读取,这种情况下每次请求也会排队。
通常情况下,磁盘在进行寻道时,其他进程会产生其他的磁盘请求。磁盘驱动程序会维护一张表,表中会记录着柱面号当作索引,每个柱面未完成的请求会形成链表,链表头存放在表的相应表项中。
一种对先来先服务的算法改良的方案是使用 最短路径优先(SSF) 算法,下面描述了这个算法。
假如我们在对磁道 6 号进行寻址时,同时发生了对 11 , 2 , 4, 14, 8, 15, 3 的请求,如果采用先来先服务的原则,如下图所示
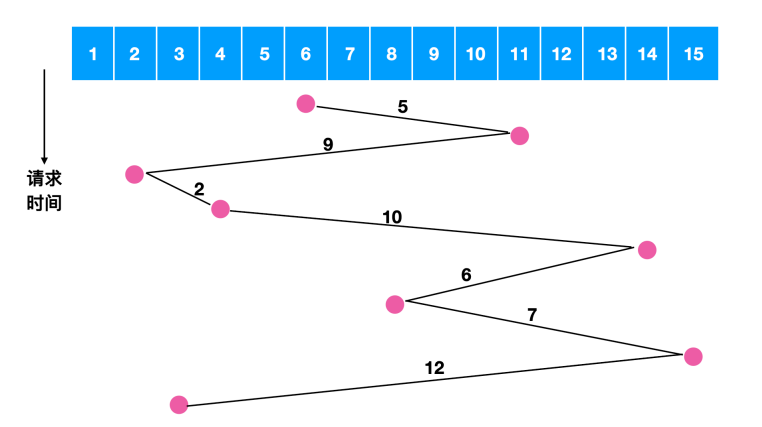
我们可以计算一下磁盘臂所跨越的磁盘数量为 5 + 9 + 2 + 10 + 6 + 7 + 12 = 51,相当于是跨越了 51 次盘面,如果使用最短路径优先,我们来计算一下跨越的盘面
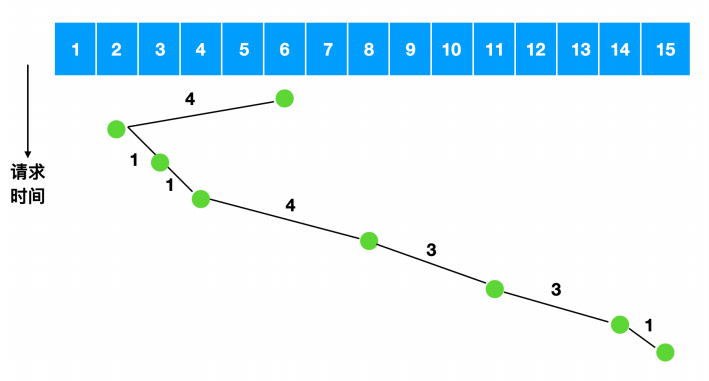
跨越的磁盘数量为 4 + 1 + 1 + 4 + 3 + 3 + 1 = 17 ,相比 51 足足省了两倍的时间。
但是,最短路径优先的算法也不是完美无缺的,这种算法照样存在问题,那就是优先级 问题,
这里有一个原型可以参考就是我们日常生活中的电梯,电梯使用一种电梯算法(elevator algorithm) 来进行调度,从而满足协调效率和公平性这两个相互冲突的目标。电梯一般会保持向一个方向移动,直到在那个方向上没有请求为止,然后改变方向。
电梯算法需要维护一个二进制位,也就是当前的方向位:UP(向上)或者是 DOWN(向下)。当一个请求处理完成后,磁盘或电梯的驱动程序会检查该位,如果此位是 UP 位,磁盘臂或者电梯仓移到下一个更高跌未完成的请求。如果高位没有未完成的请求,则取相反方向。当方向位是 DOWN 时,同时存在一个低位的请求,磁盘臂会转向该点。如果不存在的话,那么它只是停止并等待。
我们举个例子来描述一下电梯算法,比如各个柱面得到服务的顺序是 4,7,10,14,9,6,3,1 ,那么它的流程图如下
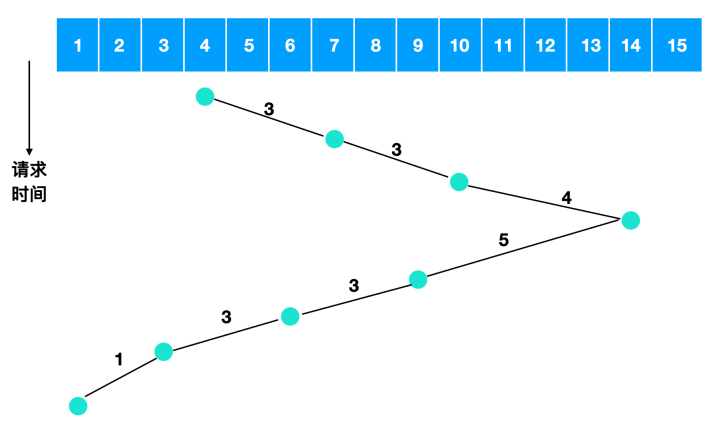
所以电梯算法需要跨越的盘面数量是 3 + 3 + 4 + 5 + 3 + 3 + 1 = 22
电梯算法通常情况下不如 SSF 算法。
错误处理
一般坏块有两种处理办法,一种是在控制器中进行处理;一种是在操作系统层面进行处理。
这两种方法经常替换使用,比如一个具有 30 个数据扇区和两个备用扇区的磁盘,其中扇区 4 是有瑕疵的。
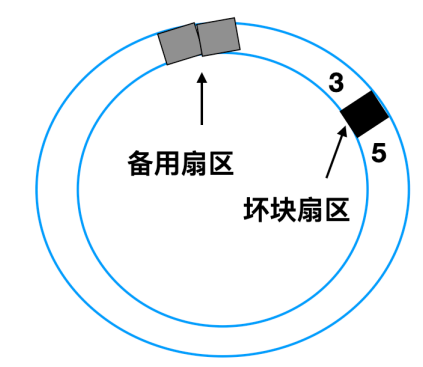
控制器能做的事情就是将备用扇区之一重新映射。
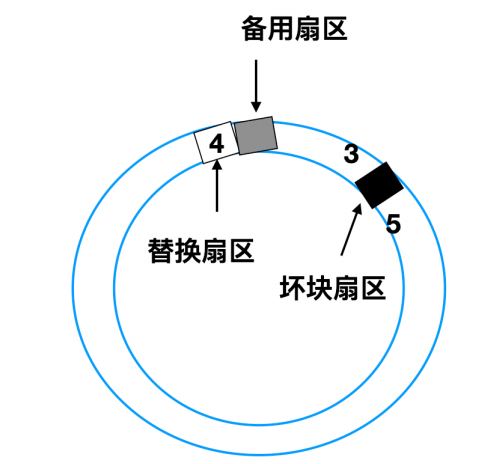
还有一种处理方式是将所有的扇区都向上移动一个扇区
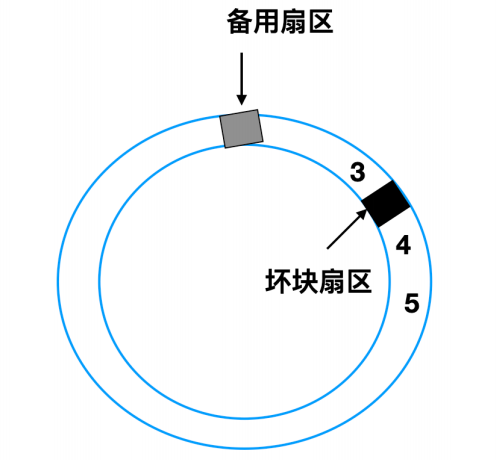
上面这这两种情况下控制器都必须知道哪个扇区,可以通过内部的表来跟踪这一信息,或者通过重写前导码来给出重新映射的扇区号。如果是重写前导码,那么涉及移动的方式必须重写后面所有的前导码,但是最终会提供良好的性能。
稳定存储器
磁盘经常会出现错误,导致好的扇区会变成坏扇区,驱动程序也有可能挂掉。RAID 可以对扇区出错或者是驱动器崩溃提出保护,然而 RAID 却不能对坏数据中的写错误提供保护,也不能对写操作期间的崩溃提供保护,这样就会破坏原始数据。
我们期望磁盘能够准确无误的工作,但是事实情况是不可能的,但是我们能够知道的是,一个磁盘子系统具有如下特性:当一个写命令发给它时,磁盘要么正确地写数据,要么什么也不做,让现有的数据完整无误的保留。这样的系统称为 稳定存储器(stable storage)。 稳定存储器的目标就是不惜一切代价保证磁盘的一致性。
稳定存储器使用两个一对相同的磁盘,对应的块一同工作形成一个无差别的块。稳定存储器为了实现这个目的,定义了下面三种操作:
稳定写(stable write)稳定读(stable read)
崩溃恢复(crash recovery)
时钟
时钟(Clocks) 也被称为定时器(timers),时钟/定时器对任何程序系统来说都是必不可少的。时钟负责维护时间、防止一个进程长期占用 CPU 时间等其他功能。时钟软件(clock software) 也是一种设备驱动的方式。下面我们就来对时钟进行介绍,一般都是先讨论硬件再介绍软件,采用由下到上的方式,也是告诉你,底层是最重要的。
时钟硬件
在计算机中有两种类型的时钟,这些时钟与现实生活中使用的时钟完全不一样。
- 比较简单的一种时钟被连接到 110 V 或 220 V 的电源线上,这样每个
电压周期会产生一个中断,大概是 50 - 60 HZ。这些时钟过去一直占据支配地位。 - 另外的一种时钟由晶体振荡器、计数器和寄存器组成,示意图如下所示
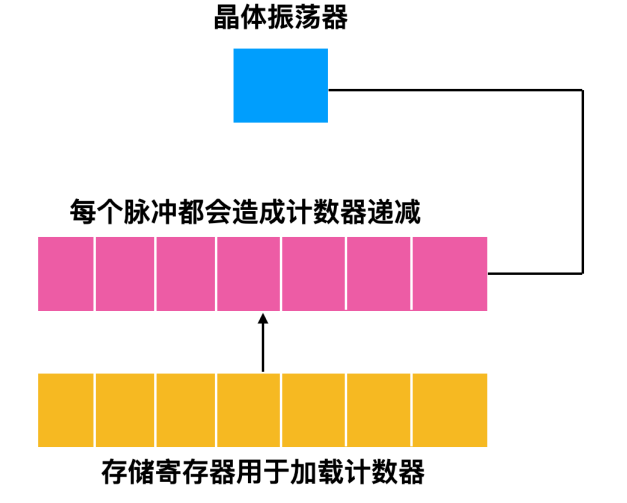
这种时钟称为可编程时钟 ,可编程时钟有两种模式,一种是 一键式(one-shot mode),当时钟启动时,会把存储器中的值复制到计数器中,然后,每次晶体的振荡器的脉冲都会使计数器 -1。当计数器变为 0 时,会产生一个中断,并停止工作,直到软件再一次显示启动。还有一种模式时 方波(square-wave mode) 模式,在这种模式下,当计数器变为 0 并产生中断后,存储寄存器的值会自动复制到计数器中,这种周期性的中断称为一个时钟周期。
时钟软件
时钟硬件所做的工作只是根据已知的时间间隔产生中断,而其他的工作都是由时钟软件来完成,一般操作系统的不同,时钟软件的具体实现也不同,但是一般都会包括以下这几点
- 维护一天的时间
- 阻止进程运行的时间超过其指定时间
- 统计 CPU 的使用情况
- 处理用户进程的警告系统调用
- 为系统各个部分提供看门狗定时器
- 完成概要剖析,监视和信息收集
软定时器
时钟软件也被称为可编程时钟,可以设置它以程序需要的任何速率引发中断。时钟软件触发的中断是一种硬中断,但是某些应用程序对于硬中断来说是不可接受的。
这时候就需要一种软定时器(soft timer) 避免了中断,无论何时当内核因为某种原因呢在运行时,它返回用户态之前都会检查时钟来了解软定时器是否到期。如果软定时器到期,则执行被调度的事件也无需切换到内核态,因为本身已经处于内核态中。这种方式避免了频繁的内核态和用户态之前的切换,提高了程序运行效率。
软定时器因为不同的原因切换进入内核态的速率不同,原因主要有
- 系统调用
- TLB 未命中
- 缺页异常
- I/O 中断
- CPU 变得空闲
死锁问题也是操作系统非常重要的一类问题
资源
大部分的死锁都和资源有关,在进程对设备、文件具有独占性(排他性)时会产生死锁。我们把这类需要排他性使用的对象称为资源(resource)。资源主要分为 可抢占资源和不可抢占资源
可抢占资源和不可抢占资源
资源主要有可抢占资源和不可抢占资源。可抢占资源(preemptable resource) 可以从拥有它的进程中抢占而不会造成其他影响,内存就是一种可抢占性资源,任何进程都能够抢先获得内存的使用权。
不可抢占资源(nonpreemtable resource) 指的是除非引起错误或者异常,否则进程无法抢占指定资源,这种不可抢占的资源比如有光盘,在进程执行调度的过程中,其他进程是不能得到该资源的。
死锁
如果要对死锁进行一个定义的话,下面的定义比较贴切
如果一组进程中的每个进程都在等待一个事件,而这个事件只能由该组中的另一个进程触发,这种情况会导致死锁。
资源死锁的条件
针对我们上面的描述,资源死锁可能出现的情况主要有
- 互斥条件:每个资源都被分配给了一个进程或者资源是可用的
- 保持和等待条件:已经获取资源的进程被认为能够获取新的资源
- 不可抢占条件:分配给一个进程的资源不能强制的从其他进程抢占资源,它只能由占有它的进程显示释放
- 循环等待:死锁发生时,系统中一定有两个或者两个以上的进程组成一个循环,循环中的每个进程都在等待下一个进程释放的资源。
发生死锁时,上面的情况必须同时会发生。如果其中任意一个条件不会成立,死锁就不会发生。可以通过破坏其中任意一个条件来破坏死锁,下面这些破坏条件就是我们探讨的重点
死锁模型
Holt 在 1972 年提出对死锁进行建模,建模的标准如下:
- 圆形表示进程
- 方形表示资源
从资源节点到进程节点表示资源已经被进程占用,如下图所示
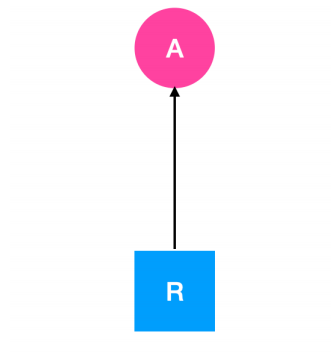
在上图中表示当前资源 R 正在被 A 进程所占用
由进程节点到资源节点的有向图表示当前进程正在请求资源,并且该进程已经被阻塞,处于等待这个资源的状态
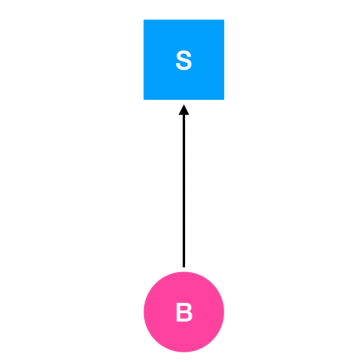
在上图中,表示的含义是进程 B 正在请求资源 S 。Holt 认为,死锁的描述应该如下
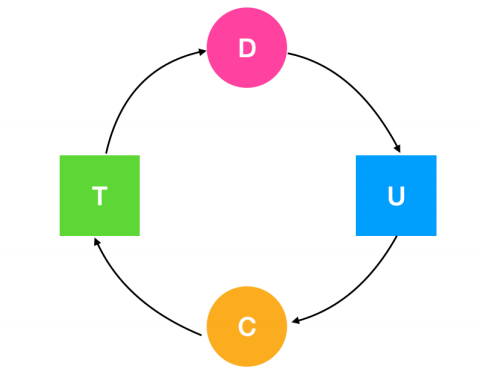
这是一个死锁的过程,进程 C 等待资源 T 的释放,资源 T 却已经被进程 D 占用,进程 D 等待请求占用资源 U ,资源 U 却已经被线程 C 占用,从而形成环。
有四种处理死锁的策略:
- 忽略死锁带来的影响(惊呆了)
- 检测死锁并回复死锁,死锁发生时对其进行检测,一旦发生死锁后,采取行动解决问题
- 通过仔细分配资源来避免死锁
- 通过破坏死锁产生的四个条件之一来避免死锁
下面我们分别介绍一下这四种方法
鸵鸟算法
最简单的解决办法就是使用鸵鸟算法(ostrich algorithm),把头埋在沙子里,假装问题根本没有发生。每个人看待这个问题的反应都不同。数学家认为死锁是不可接受的,必须通过有效的策略来防止死锁的产生。工程师想要知道问题发生的频次,系统因为其他原因崩溃的次数和死锁带来的严重后果。如果死锁发生的频次很低,而经常会由于硬件故障、编译器错误等其他操作系统问题导致系统崩溃,那么大多数工程师不会修复死锁。
死锁检测和恢复
第二种技术是死锁的检测和恢复。这种解决方式不会尝试去阻止死锁的出现。相反,这种解决方案会希望死锁尽可能的出现,在监测到死锁出现后,对其进行恢复。下面我们就来探讨一下死锁的检测和恢复的几种方式
每种类型一个资源的死锁检测方式
每种资源类型都有一个资源是什么意思?我们经常提到的打印机就是这样的,资源只有打印机,但是设备都不会超过一个。
可以通过构造一张资源分配表来检测这种错误,比如我们上面提到的

如果这张图包含了一个或一个以上的环,那么死锁就存在,处于这个环中任意一个进程都是死锁的进程。
每种类型多个资源的死锁检测方式
如果有多种相同的资源存在,就需要采用另一种方法来检测死锁。可以通过构造一个矩阵来检测从 P1 -> Pn 这 n 个进程中的死锁。
现在我们提供一种基于矩阵的算法来检测从 P1 到 Pn 这 n 个进程中的死锁。假设资源类型为 m,E1 代表资源类型1,E2 表示资源类型 2 ,Ei 代表资源类型 i (1 <= i <= m)。E 表示的是 现有资源向量(existing resource vector),代表每种已存在的资源总数。
现在我们就需要构造两个数组:C 表示的是当前分配矩阵(current allocation matrix) ,R 表示的是 请求矩阵(request matrix)。Ci 表示的是 Pi 持有每一种类型资源的资源数。所以,Cij 表示 Pi 持有资源 j 的数量。Rij 表示 Pi 所需要获得的资源 j 的数量

一般来说,已分配资源 j 的数量加起来再和所有可供使用的资源数相加 = 该类资源的总数。
死锁的检测就是基于向量的比较。每个进程起初都是没有被标记过的,算法会开始对进程做标记,进程被标记后说明进程被执行了,不会进入死锁,当算法结束时,任何没有被标记过的进程都会被判定为死锁进程。
上面我们探讨了两种检测死锁的方式,那么现在你知道怎么检测后,你何时去做死锁检测呢?一般来说,有两个考量标准:
- 每当有资源请求时就去检测,这种方式会占用昂贵的 CPU 时间。
- 每隔 k 分钟检测一次,或者当 CPU 使用率降低到某个标准下去检测。考虑到 CPU 效率的原因,如果死锁进程达到一定数量,就没有多少进程可以运行,所以 CPU 会经常空闲。
从死锁中恢复
上面我们探讨了如何检测进程死锁,我们最终的目的肯定是想让程序能够正常的运行下去,所以针对检测出来的死锁,我们要对其进行恢复,下面我们会探讨几种死锁的恢复方式
通过抢占进行恢复
在某些情况下,可能会临时将某个资源从它的持有者转移到另一个进程。比如在不通知原进程的情况下,将某个资源从进程中强制取走给其他进程使用,使用完后又送回。这种恢复方式一般比较困难而且有些简单粗暴,并不可取。
通过回滚进行恢复
如果系统设计者和机器操作员知道有可能发生死锁,那么就可以定期检查流程。进程的检测点意味着进程的状态可以被写入到文件以便后面进行恢复。检测点不仅包含存储映像(memory image),还包含资源状态(resource state)。一种更有效的解决方式是不要覆盖原有的检测点,而是每出现一个检测点都要把它写入到文件中,这样当进程执行时,就会有一系列的检查点文件被累积起来。
为了进行恢复,要从上一个较早的检查点上开始,这样所需要资源的进程会回滚到上一个时间点,在这个时间点上,死锁进程还没有获取所需要的资源,可以在此时对其进行资源分配。
杀死进程恢复
最简单有效的解决方案是直接杀死一个死锁进程。但是杀死一个进程可能照样行不通,这时候就需要杀死别的资源进行恢复。
另外一种方式是选择一个环外的进程作为牺牲品来释放进程资源。
死锁避免
我们上面讨论的是如何检测出现死锁和如何恢复死锁,下面我们探讨几种规避死锁的方式
单个资源的银行家算法
银行家算法是 Dijkstra 在 1965 年提出的一种调度算法,它本身是一种死锁的调度算法。它的模型是基于一个城镇中的银行家,银行家向城镇中的客户承诺了一定数量的贷款额度。算法要做的就是判断请求是否会进入一种不安全的状态。如果是,就拒绝请求,如果请求后系统是安全的,就接受该请求。
类似的,还有多个资源的银行家算法,读者可以自行了解。
破坏死锁
死锁本质上是无法避免的,因为它需要获得未知的资源和请求,但是死锁是满足四个条件后才出现的,它们分别是
- 互斥
- 保持和等待
- 不可抢占
- 循环等待
我们分别对这四个条件进行讨论,按理说破坏其中的任意一个条件就能够破坏死锁
破坏互斥条件
我们首先考虑的就是破坏互斥使用条件。如果资源不被一个进程独占,那么死锁肯定不会产生。如果两个打印机同时使用一个资源会造成混乱,打印机的解决方式是使用 假脱机打印机(spooling printer) ,这项技术可以允许多个进程同时产生输出,在这种模型中,实际请求打印机的唯一进程是打印机守护进程,也称为后台进程。后台进程不会请求其他资源。我们可以消除打印机的死锁。
后台进程通常被编写为能够输出完整的文件后才能打印,假如两个进程都占用了假脱机空间的一半,而这两个进程都没有完成全部的输出,就会导致死锁。
因此,尽量做到尽可能少的进程可以请求资源。
破坏保持等待的条件
第二种方式是如果我们能阻止持有资源的进程请求其他资源,我们就能够消除死锁。一种实现方式是让所有的进程开始执行前请求全部的资源。如果所需的资源可用,进程会完成资源的分配并运行到结束。如果有任何一个资源处于频繁分配的情况,那么没有分配到资源的进程就会等待。
很多进程无法在执行完成前就知道到底需要多少资源,如果知道的话,就可以使用银行家算法;还有一个问题是这样无法合理有效利用资源。
还有一种方式是进程在请求其他资源时,先释放所占用的资源,然后再尝试一次获取全部的资源。
破坏不可抢占条件
破坏不可抢占条件也是可以的。可以通过虚拟化的方式来避免这种情况。
破坏循环等待条件
现在就剩最后一个条件了,循环等待条件可以通过多种方法来破坏。一种方式是制定一个标准,一个进程在任何时候只能使用一种资源。如果需要另外一种资源,必须释放当前资源。对于需要将大文件从磁带复制到打印机的过程,此限制是不可接受的。
另一种方式是将所有的资源统一编号,如下图所示

进程可以在任何时间提出请求,但是所有的请求都必须按照资源的顺序提出。如果按照此分配规则的话,那么资源分配之间不会出现环。
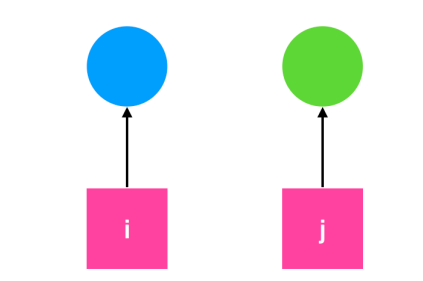
尽管通过这种方式来消除死锁,但是编号的顺序不可能让每个进程都会接受。
其他问题
下面我们来探讨一下其他问题,包括 通信死锁、活锁是什么、饥饿问题和两阶段加锁
两阶段加锁
虽然很多情况下死锁的避免和预防都能处理,但是效果并不好。随着时间的推移,提出了很多优秀的算法用来处理死锁。例如在数据库系统中,一个经常发生的操作是请求锁住一些记录,然后更新所有锁定的记录。当同时有多个进程运行时,就会有死锁的风险。
一种解决方式是使用 两阶段提交(two-phase locking)。顾名思义分为两个阶段,一阶段是进程尝试一次锁定它需要的所有记录。如果成功后,才会开始第二阶段,第二阶段是执行更新并释放锁。第一阶段并不做真正有意义的工作。
如果在第一阶段某个进程所需要的记录已经被加锁,那么该进程会释放所有锁定的记录并重新开始第一阶段。从某种意义上来说,这种方法类似于预先请求所有必需的资源或者是在进行一些不可逆的操作之前请求所有的资源。
不过在一般的应用场景中,两阶段加锁的策略并不通用。如果一个进程缺少资源就会半途中断并重新开始的方式是不可接受的。
通信死锁
我们上面一直讨论的是资源死锁,资源死锁是一种死锁类型,但并不是唯一类型,还有通信死锁,也就是两个或多个进程在发送消息时出现的死锁。进程 A 给进程 B 发了一条消息,然后进程 A 阻塞直到进程 B 返回响应。假设请求消息丢失了,那么进程 A 在一直等着回复,进程 B 也会阻塞等待请求消息到来,这时候就产生死锁。
尽管会产生死锁,但是这并不是一个资源死锁,因为 A 并没有占据 B 的资源。事实上,通信死锁并没有完全可见的资源。根据死锁的定义来说:每个进程因为等待其他进程引起的事件而产生阻塞,这就是一种死锁。相较于最常见的通信死锁,我们把上面这种情况称为通信死锁(communication deadlock)。
通信死锁不能通过调度的方式来避免,但是可以使用通信中一个非常重要的概念来避免:超时(timeout)。在通信过程中,只要一个信息被发出后,发送者就会启动一个定时器,定时器会记录消息的超时时间,如果超时时间到了但是消息还没有返回,就会认为消息已经丢失并重新发送,通过这种方式,可以避免通信死锁。
但是并非所有网络通信发生的死锁都是通信死锁,也存在资源死锁,下面就是一个典型的资源死锁。
当一个数据包从主机进入路由器时,会被放入一个缓冲区,然后再传输到另外一个路由器,再到另一个,以此类推直到目的地。缓冲区都是资源并且数量有限。如下图所示,每个路由器都有 10 个缓冲区(实际上有很多)。
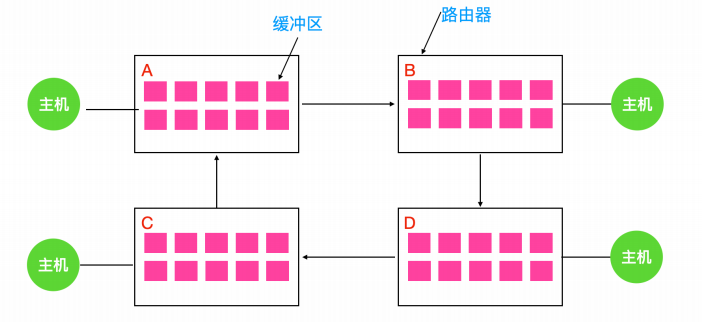
假如路由器 A 的所有数据需要发送到 B ,B 的所有数据包需要发送到 D,然后 D 的所有数据包需要发送到 A 。没有数据包可以移动,因为在另一端没有缓冲区可用,这就是一个典型的资源死锁。
活锁
某些情况下,当进程意识到它不能获取所需要的下一个锁时,就会尝试礼貌的释放已经获得的锁,然后等待非常短的时间再次尝试获取。可以想像一下这个场景:当两个人在狭路相逢的时候,都想给对方让路,相同的步调会导致双方都无法前进。
现在假想有一对并行的进程用到了两个资源。它们分别尝试获取另一个锁失败后,两个进程都会释放自己持有的锁,再次进行尝试,这个过程会一直进行重复。很明显,这个过程中没有进程阻塞,但是进程仍然不会向下执行,这种状况我们称之为 活锁(livelock)。
饥饿
与死锁和活锁的一个非常相似的问题是 饥饿(starvvation)。想象一下你什么时候会饿?一段时间不吃东西是不是会饿?对于进程来讲,最重要的就是资源,如果一段时间没有获得资源,那么进程会产生饥饿,这些进程会永远得不到服务。
我们假设打印机的分配方案是每次都会分配给最小文件的进程,那么要打印大文件的进程会永远得不到服务,导致进程饥饿,进程会无限制的推后,虽然它没有阻塞。
文章评论区
来过,就留下你的脚印吧~