爬虫架构和Scrapy框架使用
一、爬虫基本架构url管理模块就是管理自己爬取的的网页不要重复爬取,避免爬取进入死循环使用python当中的set数据结构网页下载模块将对应的url模块下载到本地或者读入内存实现方式通过url下载from urllib.request import urlopen test_url = "h...
2020年8月29日
更新于 2024年11月17日
417字
一、爬虫基本架构
url管理模块
- 就是管理自己爬取的的网页不要重复爬取,避免爬取进入死循环
- 使用python当中的set数据结构
网页下载模块
将对应的url模块下载到本地或者读入内存
实现方式
- 通过url下载
from urllib.request import urlopen test_url = "https://wztlink1013.github.io" response = urlopen(test_url) print (response.getcode()) # 200 表示访问成功 print (response.read())
- 通过Request访问
- 通过cookie访问
网页解析模块
从已经下载的网页中爬取数据,实现方式有:
- 正则表达式
- html.parser
- BeautifulSoup:结构化解析网页
- lxml
- 结构化解析
- DOM(Document Object Model),树形结构,就是html的基本骨架
二、BeautifulSoup解析网页
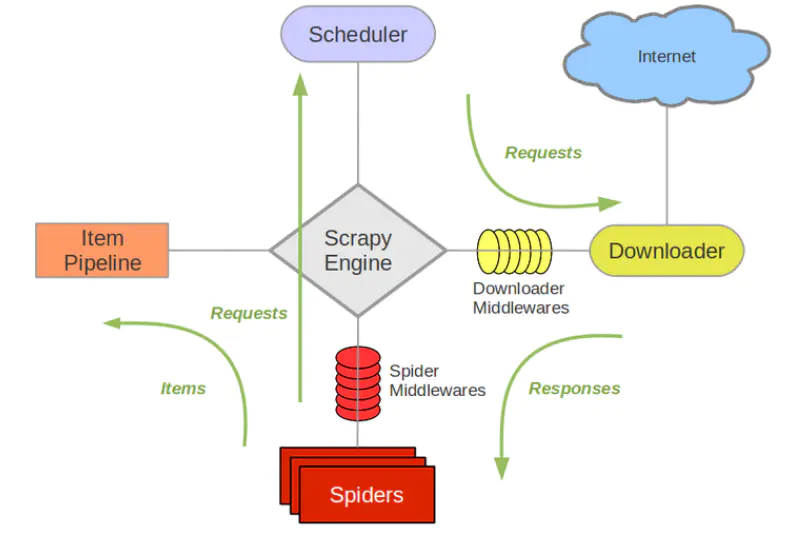
三、Scrapy
Scrapy基础
- 是一个爬虫框架,同时易扩展,可以添加新的模块达到自定义扩展
- 输出格式多样:json,csv,xml等
- 自动处理编码
Scrapy框架架构图
下载方法以及问题,在anaconda博客中
四、Scrapy使用
使用SOP
- 创建工程
- 键入
cmdcd到需要下载的目录下 - 输入
scrapy startproject tutorial(最后是项目名字) - !此后所有有关命令的操作,均在下一级文件夹下,也有是有cfg文件后缀的文件夹下
- 定义Item,构造爬取的对象
- 编写spider,爬虫主体
scrapy genspider amazon_spider https://……
- pipelines,默认return item
- 编写其他配置,其中pipeline用于处理爬取后所得到的结果
- 执行爬虫
scrapy crawl amazon_spider
常用命令
参考
- 查看其官方文档
- 简书
文章评论区
来过,就留下你的脚印吧~